Overview¶
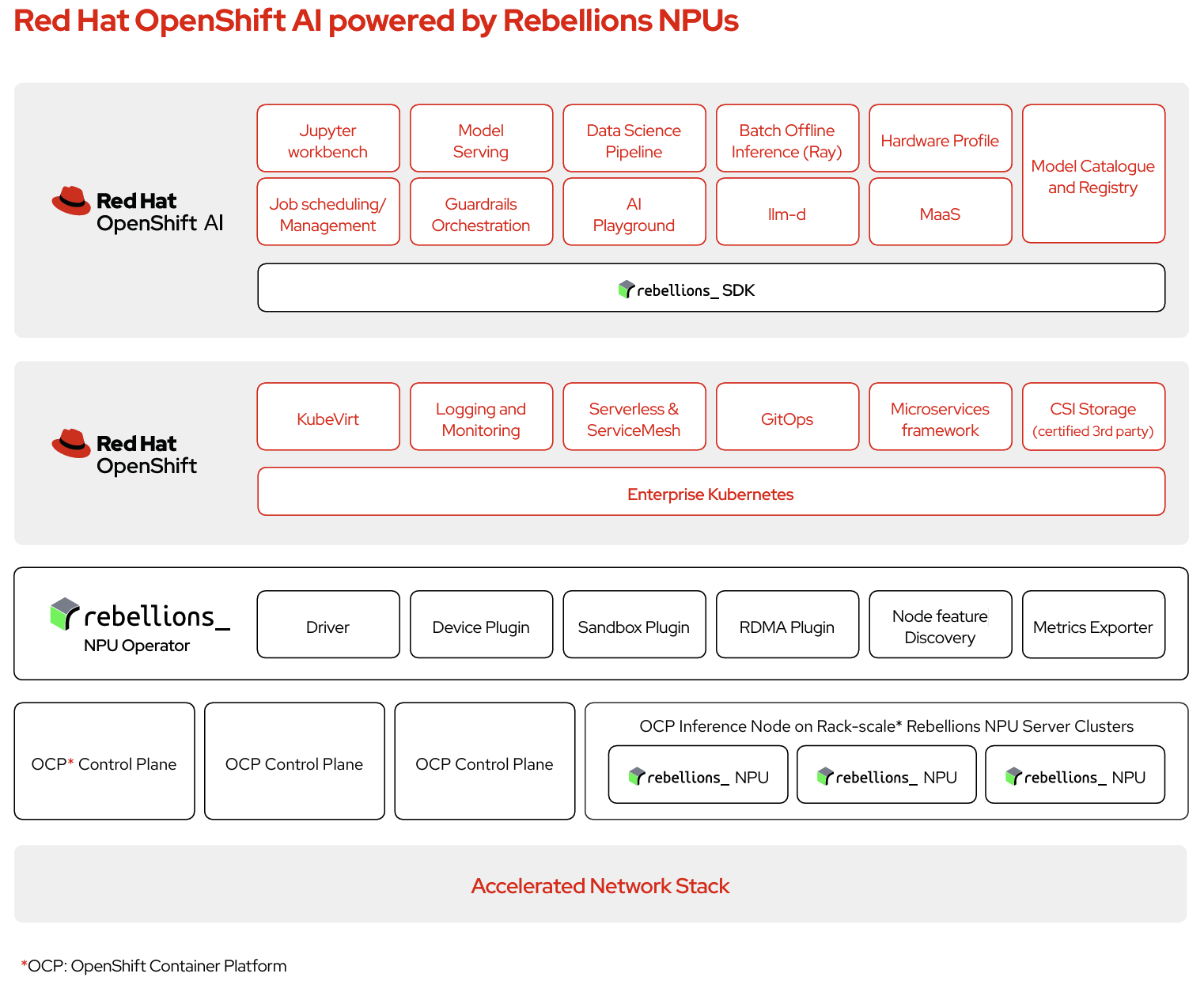
Organizations scaling generative AI face rising infrastructure costs, deployment complexity, and strict security requirements. The Red Hat AI Enterprise with Rebellions partnership provides a validated, energy-efficient NPU inference platform.
By integrating RHOAI1 vLLM RBLN image2 with RBLN NPU Operator into Red Hat OpenShift AI, this solution streamlines state-of-the-art AI model deployment for end-to-end LLM inference experience and ensures consistent performance across enterprise environments.
- Enterprise-ready AI at scale: Run large language models and inference workloads with high throughput, low latency, and strong power efficiency, using vLLM integrated with Rebellions’ rack-scale NPU solutions for distributed processing.
- Secure and compliant: Keep data on-premises and support regulatory requirements with Red Hat’s trusted platform and Rebellions’ secure hardware.
- Simplified operations: Manage NPUs in line with familiar GPU-style workflows on Red Hat’s unified platform, reducing operational complexity and accelerating adoption.
- Flexible and scalable: Deploy close to your data—from core data centers to the edge—with linear scale-out where the architecture allows.
The initial release of RHOAI vLLM RBLN Image is based on Red Hat OpenShift 4.20.15 and Red Hat OpenShift AI 3.3. The key components are as follows.
- RHOAI vLLM RBLN Image (container image)
- vLLM 0.13.0
- vLLM RBLN 0.10.1 (custom)
- RBLN PyTorch 0.1.7 (custom)
- RBLN Compiler 0.10.2 (custom)
Supported Features¶
vLLM RBLN aims for full parity with upstream vLLM capabilities. The following section defines key terms used in this document.
- TP: Tensor Parallelism, which splits a layer across NPUs to enable larger model support and improve a single-request latency
- RSD: A Rebellions-specific Tensor Parallelism based on Rebellions Scalable Design architecture. For detail, refer to What is RSD?.
- DP: Data Parallelism, which replicates the model across NPUs and splits incoming requests to increase throughput
- EP: Expert Parallelism, which distributes experts across NPUs and route tokens to scale Mixture-of-Expert (MoE) efficiently
Note
- RSD incorporates TP concepts but is orthogonal to vLLM's standard tensor parallelism (TP) meaning the two operate independently and can be used together.
- VLLM_RBLN_TP_SIZE: Environmental variable that specifies the TP size used within RSD of vLLM RBLN. For example, for RSD4, set this value to 4 in the
envsection of Model deployment wizard.
The following table outlines the capabilities supported within the vLLM RBLN container image.
- ✅ = vLLM equivalent
- 🟠 = Partial compatibility
| Feature | Status | Details |
|---|---|---|
| Paged Attention | ✅ | |
| Continuous Batching | ✅ | |
| Chunked Prefill | 🟠 | Prefill and decode are not executed concurrently; the stages alternate. |
| Structured Output | ✅ | |
| Automatic Prefix Caching | 🟠 | Partial support |
| Tensor Parallelism | 🟠 | Supported for dense models; provides measurable performance improvements when enabled. When RSD is available, use RSD before tensor parallelism (TP) for best results. |
| Pipeline Parallelism | 🟠 | Supported for various dense models; provides validated throughput improvements. |
| Expert Parallelism + Data Parallelism | 🟠 | Supported for Mixture-of-Experts (MoE) models. |
| OpenAI-Compatible API Serving | ✅ |
For more information on each feature, please refer to the Serving Features.
Officially Supported Models¶
| Model | Model Type (Dense / MoE) |
Batch Size | Recommended Model Parallelism |
|---|---|---|---|
| skt/A.X-4.0-Light | Dense | 1,2,4,8 | RSD4 |
| meta-llama/Meta-Llama-3-8B-Instruct | Dense | 1,2,4,8 | RSD4 |
| meta-llama/Llama-3.2-3B-Instruct | Dense | 1,2,4,8 | RSD8 |
| Qwen/Qwen2.5-7B-Instruct | Dense | 1,2,4,8 | RSD4 |
| Qwen/Qwen2.5-32B-Instruct | Dense | 1,2,4,8 | RSD16 |
| Qwen/Qwen3-0.6B | Dense | 1,2,4,8 | N/A |
| Qwen/Qwen3-1.7B | Dense | 1,2,4,8 | RSD2 |
| Qwen/Qwen3-4B | Dense | 1,2,4,8 | RSD4 |
| Qwen/Qwen3-8B | Dense | 1,2,4,8 | RSD4 |
| Qwen/Qwen3-32B | Dense | 1,2,4,8 | RSD16 |
| Qwen/Qwen1.5-MoE-A2.7B | MoE | 1 | EP-DP2-RSD4, EP-TP2-RSD4 |
| Qwen/Qwen3-30B-A3B | MoE | 1 | EP-DP4-RSD4, EP-TP4-RSD4 |