개요¶
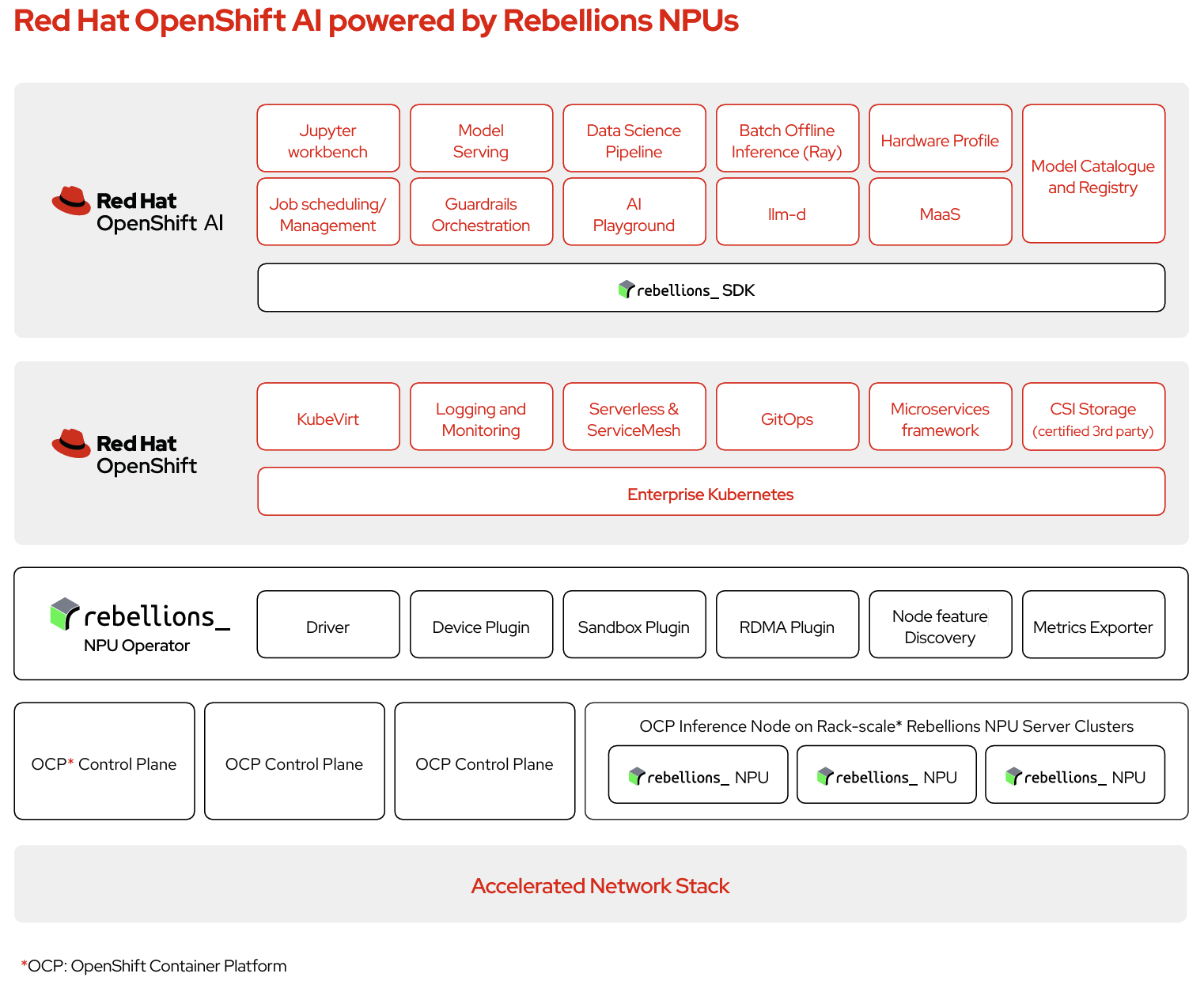
생성형 AI를 확장하는 회사는 인프라 비용 상승, 배포 복잡성, 그리고 엄격한 보안 요구 사항에 직면합니다. Red Hat AI Enterprise with Rebellions 파트너십은 에너지 효율적인 검증된 NPU 추론 플랫폼을 제공합니다.
RHOAI1 vLLM RBLN 이미지2와 RBLN NPU Operator를 Red Hat OpenShift AI에 통합함으로써, 이 솔루션은 최첨단 AI 모델 배포를 간소화하여 엔드투엔드 LLM 추론 경험을 제공하고, 기업 환경 전반에서 일관된 성능을 보장합니다.
- 엔터프라이즈급 대규모 AI: vLLM을 Rebellions의 랙 스케일 NPU 솔루션과 통합하여 분산 처리로 대규모 언어 모델 및 추론 워크로드를 높은 처리량, 낮은 지연, 우수한 전력 효율로 실행합니다.
- 보안 및 규정 준수: Red Hat의 신뢰할 수 있는 플랫폼과 Rebellions의 보안 하드웨어로 온프레미스에 데이터를 유지하고 규제 요구 사항을 충족할 수 있습니다.
- 운영 단순화: Red Hat의 통합 플랫폼에서 익숙한 GPU 스타일 워크플로에 맞춰 NPU를 관리하여 운영 복잡도를 줄이고 도입을 가속합니다.
- 유연성 및 확장성: 아키텍처가 허용하는 범위에서 선형 스케일아웃으로 코어 데이터센터부터 엣지까지 데이터에 가깝게 배포할 수 있습니다.
RHOAI vLLM RBLN Image의 초기 릴리스는 Red Hat OpenShift 4.20.15 및 Red Hat OpenShift AI 3.3을 기반으로 합니다. 주요 구성 요소는 다음과 같습니다.
- RHOAI vLLM RBLN Image (컨테이너 이미지)
- vLLM 0.13.0
- vLLM RBLN 0.10.1 (custom)
- RBLN PyTorch 0.1.7 (custom)
- RBLN Compiler 0.10.2 (custom)
지원 기능¶
vLLM RBLN은 업스트림 vLLM 기능과 완전한 동등한 기능을 제공하는 것을 목표로 합니다. 다음에서는 이 문서에서 사용하는 주요 용어를 정의합니다.
- TP: Tensor Parallelism을 의미합니다. 레이어를 NPU에 분할하여 더 큰 모델 지원과 단일 요청 지연 시간 개선을 가능하게 합니다.
- RSD: Rebellions Scalable Design 아키텍처에 기반한 Rebellions 전용 Tensor Parallelism을 의미합니다. 자세한 내용은 RSD란 무엇인가?를 참조하세요.
- DP: Data Parallelism을 의미합니다. 모델을 NPU에 복제하고 들어오는 요청을 분할하여 처리량을 높입니다.
- EP: Expert Parallelism을 의미합니다. 전문가(expert)를 NPU에 분산하고 토큰을 라우팅하여 MoE(Mixture-of-Experts)를 효율적으로 확장합니다.
Note
- RSD는 TP 개념을 포함하지만 vLLM의 표준 tensor parallelism(TP)과는 서로 무관한 개념이며, 두 방식은 독립적으로 동작하며 함께 사용할 수 있습니다.
- VLLM_RBLN_TP_SIZE: vLLM RBLN의 RSD 내에서 사용하는 TP 크기를 지정하는 환경 변수입니다. 예를 들어 RSD4의 경우 모델 배포 마법사의
env섹션에서 이 값을 4로 설정합니다.
아래 표는 vLLM RBLN 컨테이너 이미지에서 지원하는 기능을 정리한 것입니다.
- ✅ = vLLM과 동등
- 🟠 = 부분 호환
| 기능 | 상태 | 상세 |
|---|---|---|
| Paged Attention | ✅ | |
| Continuous Batching | ✅ | |
| Chunked Prefill | 🟠 | Prefill과 decode는 동시에 실행되지 않으며, 각 단계가 번갈아 수행됩니다. |
| Structured Output | ✅ | |
| Automatic Prefix Caching | 🟠 | 부분 지원 |
| Tensor Parallelism | 🟠 | Dense 모델에 대해 지원되며, 활성화 시 측정 가능한 성능 개선을 제공합니다. RSD를 사용할 수 있으면 최적 결과를 위해 tensor parallelism(TP)보다 RSD를 우선 사용하십시오. |
| Pipeline Parallelism | 🟠 | 다양한 dense 모델에 대해 지원되며, 검증된 처리량 개선을 제공합니다. |
| Expert Parallelism + Data Parallelism | 🟠 | MoE (Mixture-of-Experts) 모델에 대해 지원됩니다. |
| OpenAI 호환 API 서빙 | ✅ |
각 기능에 대한 자세한 내용은 서빙 기능을 참조하십시오.
공식 지원 모델¶
| 모델 | 모델 유형 (Dense / MoE) |
배치 크기 | 권장 모델 병렬화 |
|---|---|---|---|
| skt/A.X-4.0-Light | Dense | 1,2,4,8 | RSD4 |
| meta-llama/Meta-Llama-3-8B-Instruct | Dense | 1,2,4,8 | RSD4 |
| meta-llama/Llama-3.2-3B-Instruct | Dense | 1,2,4,8 | RSD8 |
| Qwen/Qwen2.5-7B-Instruct | Dense | 1,2,4,8 | RSD4 |
| Qwen/Qwen2.5-32B-Instruct | Dense | 1,2,4,8 | RSD16 |
| Qwen/Qwen3-0.6B | Dense | 1,2,4,8 | N/A |
| Qwen/Qwen3-1.7B | Dense | 1,2,4,8 | RSD2 |
| Qwen/Qwen3-4B | Dense | 1,2,4,8 | RSD4 |
| Qwen/Qwen3-8B | Dense | 1,2,4,8 | RSD4 |
| Qwen/Qwen3-32B | Dense | 1,2,4,8 | RSD16 |
| Qwen/Qwen1.5-MoE-A2.7B | MoE | 1 | EP-DP2-RSD4, EP-TP2-RSD4 |
| Qwen/Qwen3-30B-A3B | MoE | 1 | EP-DP4-RSD4, EP-TP4-RSD4 |