How to analyze the RBLN Profiler data using Perfetto¶
This section provides the foundation for analyzing profiling results by explaining the information displayed on the Perfetto screen.
Understanding Profiled Infos¶

Task Details¶
-
Name Structure
The RBLN Profiler uses a naming convention for tasks structured as
{sequence_index}_{layer_name}_{command_index}. This format helps identify the specific stage in a neural network layer's operation and evaluate its performance at that stage.sequence_indexrepresents the order in which a module is executed, indicating its position in a series of runtime iterations.layer_namerefers to the specific tensor-level operation being performed. In cases where multiple operations are fused, they are grouped under the label "fused()" and "+".command_indexidentifies the specific command generated by the Compiler when the operation is divided into multiple commands, distinguishing each individual command within that division.
-
Category
The RBLN profiler provides the following seven commands as Category. For more detailed information on each category, please refer to the RBLN NPU Architecture page.
HostNeural Engine ClustersNeural DMATask DMAExternal HDMADevice HDMADevice Sync
The numbers next to the command names in the Perfetto UI are internal ID values assigned by the RBLN Profiler. These numbers are unrelated to the actual performance of the RBLN NPU.
-
Flow Connection (Preceding Flows & Following Flows)
The
Preceding FlowsandFollowing Flowsdisplayed at the bottom of Perfetto represent dependencies among commands. During model compilation, these dependencies are determined to ensure that the Command Processor handles them correctly, taking the device's configuration and allocation status into account. Dependencies related to Neural DMAs are managed by the Task Manager within the Neural Engine, and, therefore, are not displayed in Perfetto.-
Between
External HDMAandTask DMA
External HDMAtransfers weight and input data from host DRAM to ATOM™ device DRAM, creating a dependency with the initialTask DMAcommand that sends data from the ATOM™ device DRAM to the on-chip Shared Memory. Similarly, since the final output data retrieved byTask DMAmust be sent back to host DRAM viaExternal HDMA, it is essential to enforce a dependency ensuring thatExternal HDMAexecutes only afterTask DMAcompletes.These visualized flows demonstrate explicit dependencies among commands. However, it doesn't imply that a command without connections has no sequential dependencies. For instance, Task Managers in each Neural Engine preside synchronization on a local hardware level. Also, there is a barrier that prevent an first
Neural Engine Clusterscommands from executing until relatedExternal HDMAcommands are done. -
Between
Neural Engine ClustersandTask DMA
The connection between the
Neural Engine ClustersandTask DMAmainly shows dependency related to transfer weights or in/output data between neural network layers, and it is designed to support each tasks accordingly. In this example, the dependency is determined by the compiler because the kernel weights need to be loaded for the givenNeural Engine Clustersoperation0_fused(bn1+conv1+relu)_1. Additionally, if the compiler determines a connection is needed between theNeural Engine ClustersandTask DMA, it is considered a dependency. For example, data generated after neural network layers computation is temporarily stored in the ATOM™ device memory due to its large size. -
Between
Device HDMAandDevice Sync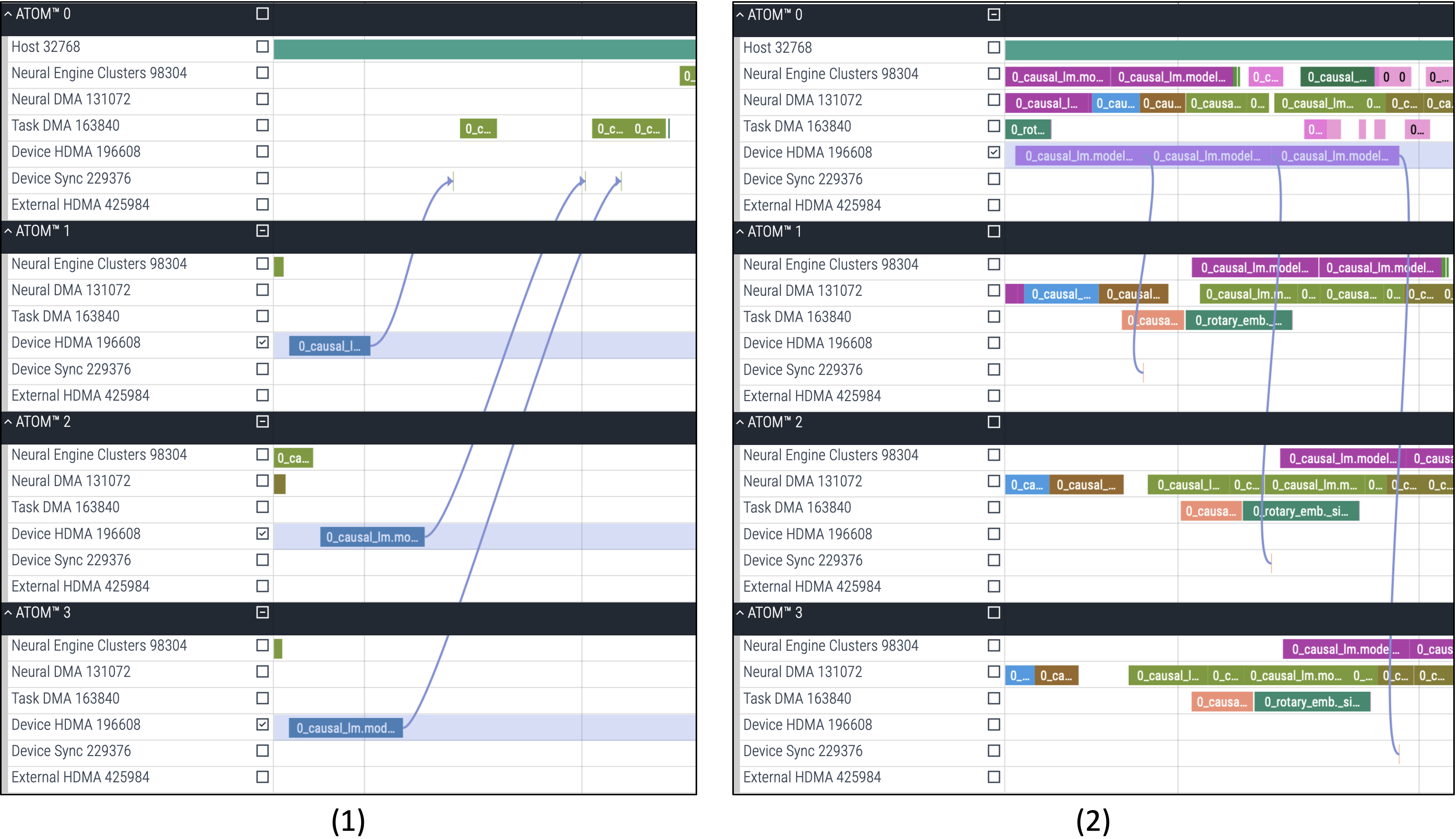
In large models using multiple ATOM™ devices, layers are divided through sharding, allowing them to run across multiple devices.
In case 1, the root ATOM™ device (node 0) synchronizes with leaf ATOM™ devices (node 1, 2, 3) via
Device HDMAto receive data. The figure (1) illustrates how data are gathered into the root ATOM™ device (node 0) throughDevice HDMA, after which the synchronization on each leaf ATOM™ device (node 1, 2, 3) is released.Conversely, in case 2, the root ATOM™ device (node 0) also synchronizes with leaf ATOM™ devices (node 1, 2, 3) via
Device HDMAto send data. The provided figure (2) illustrates how data are distributed to the leaf ATOM™ devices (node 1, 2, 3) throughDevice HDMA. Afterward, the leaf ATOM™ devices send a synchronization signal to confirm they have correctly received the data.These tensor-parallel models generate synchronization commands during compilation to establish dependencies with the
Device HDMA.
-
Naming Policy in Detail¶
Execution of a neural network can be represented as a sequence of tensor operations, and with RBLN Compiler, each tensor operation can be represented as a sequence of commands. Therefore, a sequence of commands in a visualized profiling result can be mapped to a neural network module. This section introduces the naming policy of commands in timeline.
Case 1. Matching Names with Model (PyTorch)¶
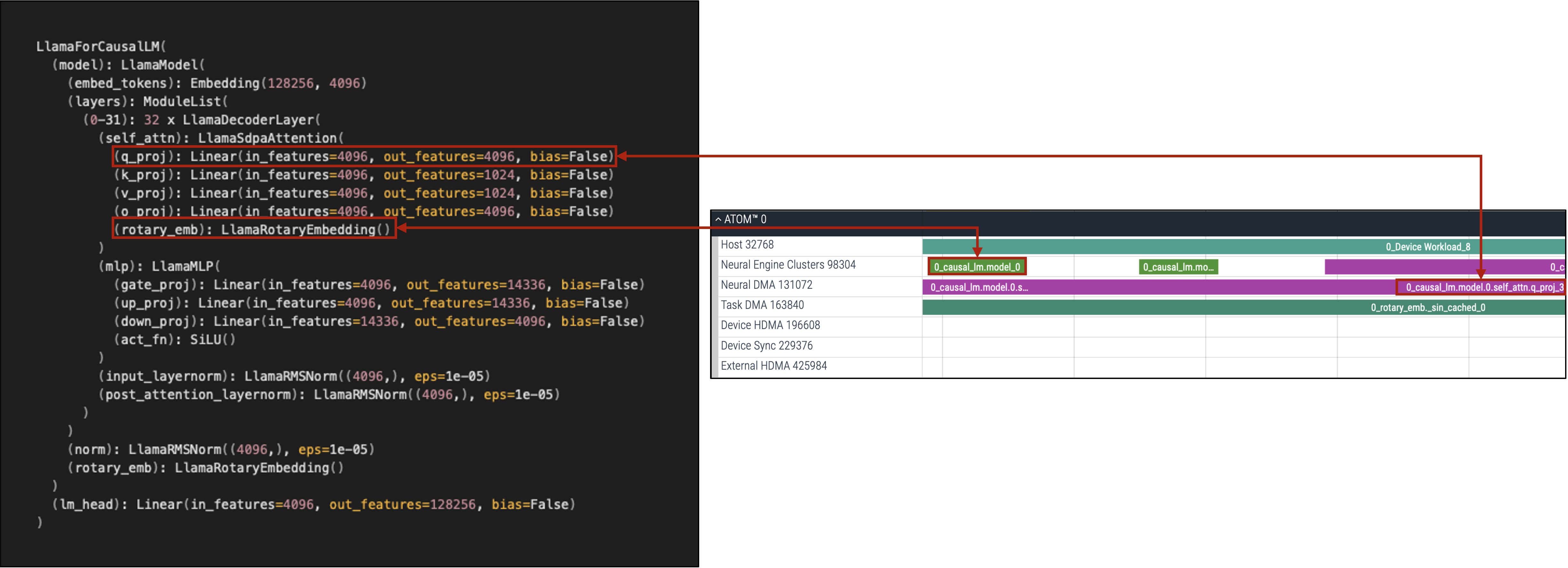
The structure of a model can be recognized from a printed specification or code-level implementation. Comparing that information with visualized nodes identifies how an operation is converted into a sequence of commands. In the above example, model.layers[0].self_attn.q_proj of a LlamaForCausalLM instance gets converted into 0_causal_lm.model.0.self_attn.q_proj.
The structure of a model and the order of its layers may differ from the actual sequence in which commands are processed. Several commands can be omitted during compilation. In that case, command indices of a single layer can be discrete. Arbitrary commands are implicitly generated during the compilation process for executing various operations on ATOM™ efficiently. In the above example, 0_causal_lm.model_0 is added to process a rotary positional embedding layer (RoPE).
Case 2. Command Generation¶

To improve performance and efficiency, RBLN Compiler supports operation fusion, which combines a sequence of operations into a single function. The command_name of a fused function will be fused(name0+name1...). In the above example, a convolution layer, a batch normalization layer and activation function layer are merged into a single function named fused(layer1.2+layer1.2.bn3+layer1.2.conv3).
A sequence of commands for processing a module shares the same command_name, and we can distinguish each of them with the command_index. Several commands such as device memory accesses on Task DMA and executions on the Neural Engine Clusters for running fused(layer1.2+layer1.2.bn3+layer1.2.conv3) are expressed in the form 0_fused(layer1.2+layer1.2.bn3+layer1.2.conv3)_{command_index}.
Case 3. Reusing Layers (PyTorch)¶

Inline operations such as torch.add, torch.nn.functional.relu are compiled without name because the model does not have their attribute names. This makes it hard to identify which commands correspond to the operations in Perfetto. To prevent this, we highly recommend using an explicit class attribute inheriting torch.nn.module instead of inline operations.
Additionally, repeatedly using a single class attribute may also create difficulties in mapping commands in Perfetto to specific operations. For example, in the ResNet50 model, as shown in the Pytorch code, there is only one explicit class attribute named self.relu in the Bottleneck module, which allocates nn.ReLU. In this case, as seen in the profiling results above, relu is omitted from the command names of the second and third Neural Engine Clusters, because the same self.relu attribute is repeatedly used in the forward function. Only the first instance retains the relu.

If you modify the forward function in the Bottleneck module to use different attributes (self.relu1, self.relu2, self.relu3), as shown in the Pytorch code above, you will notice that relu is explicitly included not only in the first Neural Engine Clusters command name (1) but also in subsequent ones (2) and (3), without being omitted.