Deep Dive¶
Understanding the RBLN Runtime and its Workflow¶
The RBLN Runtime serves as the API for executing compiled models on the RBLN NPU. It provides a direct and simplified interface to the RBLN SDK's core components and directly interacts with the underlying RBLN Driver to manage device execution, memory, and synchronization. This ensures efficient communication between the host application (your code) and the NPU hardware.
Architecture
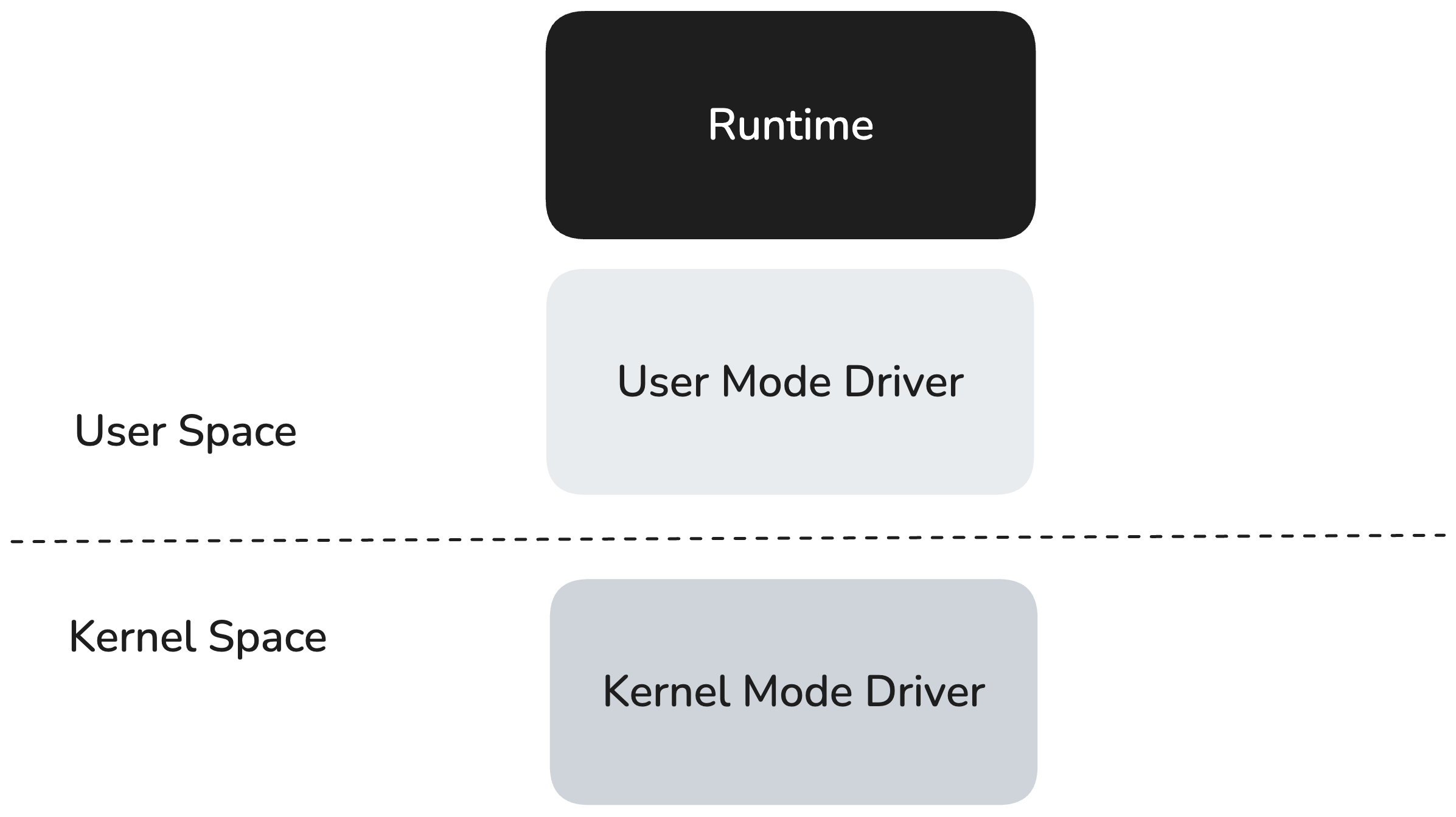
The RBLN runtime operates in the user space, running on top of the user-mode driver (UMD) and utilizing its low-level interface to communicate with the kernel-mode driver (KMD). The KMD runs in the operating system's kernel, where it handles privileged operations such as direct hardware access and scheduling.
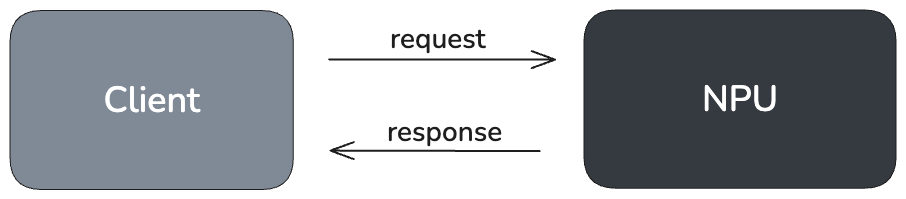
Conceptually, the runtime follows a client–server model. The host application acts as the client, making high-level API calls to request tasks such as inference, memory allocation, or synchronization. The NPU acts as the server, executing those tasks. Internally, the runtime translates host requests into low-level commands, encapsulates them in command buffers, and submits them to the RBLN driver, which schedules execution on the NPU.
A Typical RBLN Runtime Workflow¶
A typical inference workflow is streamlined into three simple steps:
- Load the compiled file: The
.rblnfile is loaded into memory. - Create the runtime instance: The creation of a rebel.Runtime() object performs the initialization procedures required for inference on the RBLN NPU.
- Run inference: The module.run() method triggers execution on the NPU.
Here is a simple code example of how to use the RBLN runtime:
.rbln file contents¶
A compiled .rbln file is an optimized container that holds all the necessary data for a neural network to run efficiently on an NPU. It's essentially a pre-packaged, ready-to-run version of your model, designed to minimize latency and maximize performance by eliminating on-the-fly compilation and resource allocation. The file's contents are categorized into three main sections: Model, Metadata, and Profile Info.
1. Model
This section contains the fundamental components of the neural network, all of which have been pre-optimized for efficient execution on the NPU.
- Compiled Graph : This is a directed acyclic graph (DAG) that represents the model's computational flow. For models from frameworks like
torch.nn.Module, the original graph is "lowered" into this optimized form. This ensures all operations, including data transfers between the host (CPU) and the NPU, are executed in the correct topological order for maximum efficiency. - Program Binary : This is the executable machine code specifically compiled for the NPU's instruction set. It contains the low-level operations that the NPU's processor can execute directly, much like an executable file for a traditional CPU.
- Command Stream : An optimized sequence of instructions containing virtual addresses that is consumed by the NPU's command processor.
- Memory & I/O : This component includes precomputed memory addresses and allocation sizes for all tensors—inputs, outputs, and intermediate data. By pre-allocating memory, the
.rblnfile eliminates the performance bottleneck of dynamic memory management during inference. - Weights : The model's weights and biases are stored in a highly optimized, pre-compiled format. This allows them to be loaded directly into the NPU's memory without any additional processing or data conversion.
Note
For large language models (LLMs), .rbln files may employ advanced optimizations like weight sharing across different models. This can significantly reduce the file size and memory footprint, making deployment more efficient. As a result, the file's final size and contents may vary depending on these applied optimizations.
2. Metadata
This section contains important structural and compilation information about the model. This data can be inspected programmatically via the RBLNCompiledModel.inspect() API, providing insights into the model's architecture and the specifics of its compilation process.
3. Profile Info
This section contains detailed profiling data, which is essential for performance analysis. This information helps developers understand how the model behaves on the NPU, identifying potential bottlenecks and areas for improvement.
RBLN command structure¶
The RBLN Runtime uses a structured, low-level command system to orchestrate tasks on the RBLN NPU, similar to how modern graphics APIs manage GPU work.
Command buffers¶
A Command Buffer is the fundamental unit of work submission in the RBLN Runtime. It encapsulates one or more commands that represent a single, atomic task. The RBLN runtime creates these buffers and then encodes them with the precompiled Command Stream and Tensor information stored in the .rbln file.
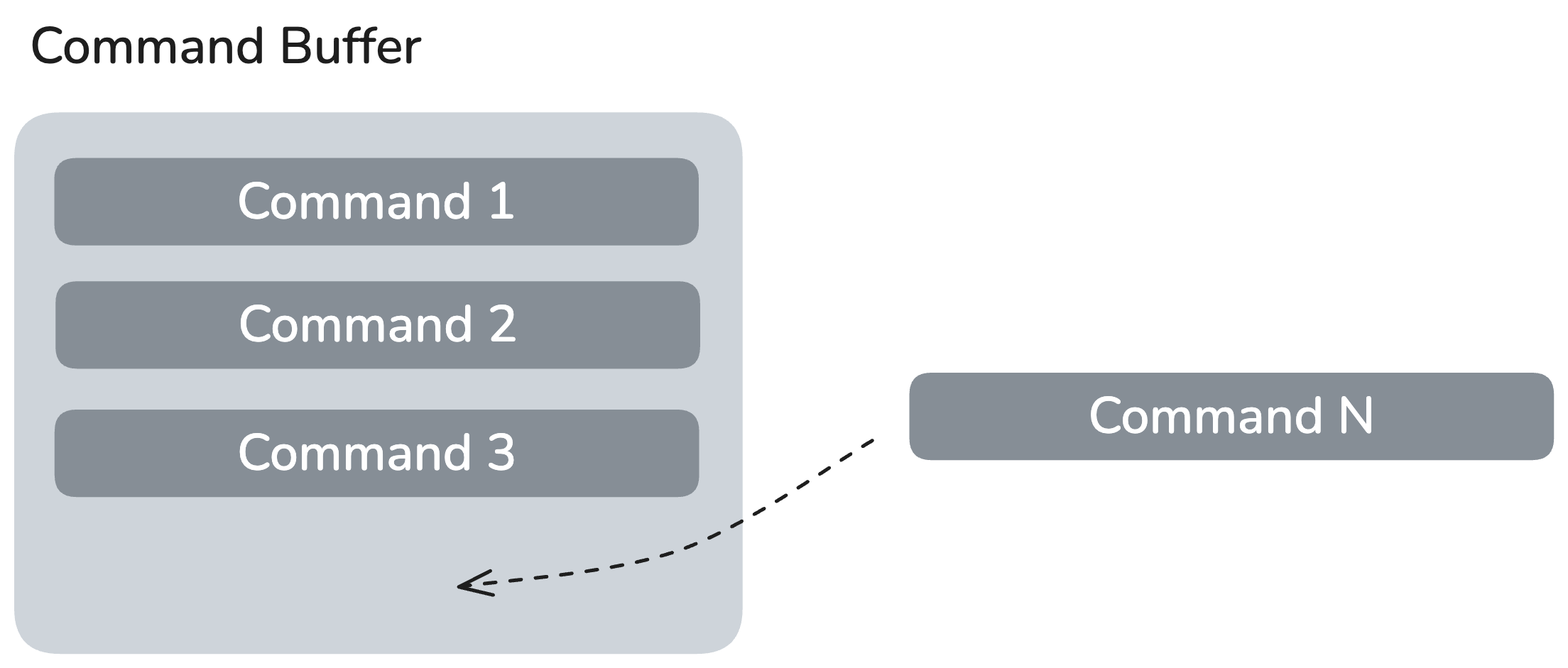
Lifecycle of an RBLN Command Buffer
-
Creation: During runtime initialization, the runtime creates one or more command buffers. Each buffer represents a logical chunk of the model's execution flow.
-
Encoding: The runtime populates each buffer with specific commands, such as tensor transfers (HDMA), compute kernel dispatches, and synchronization points (barriers) required for a complete inference pass.
-
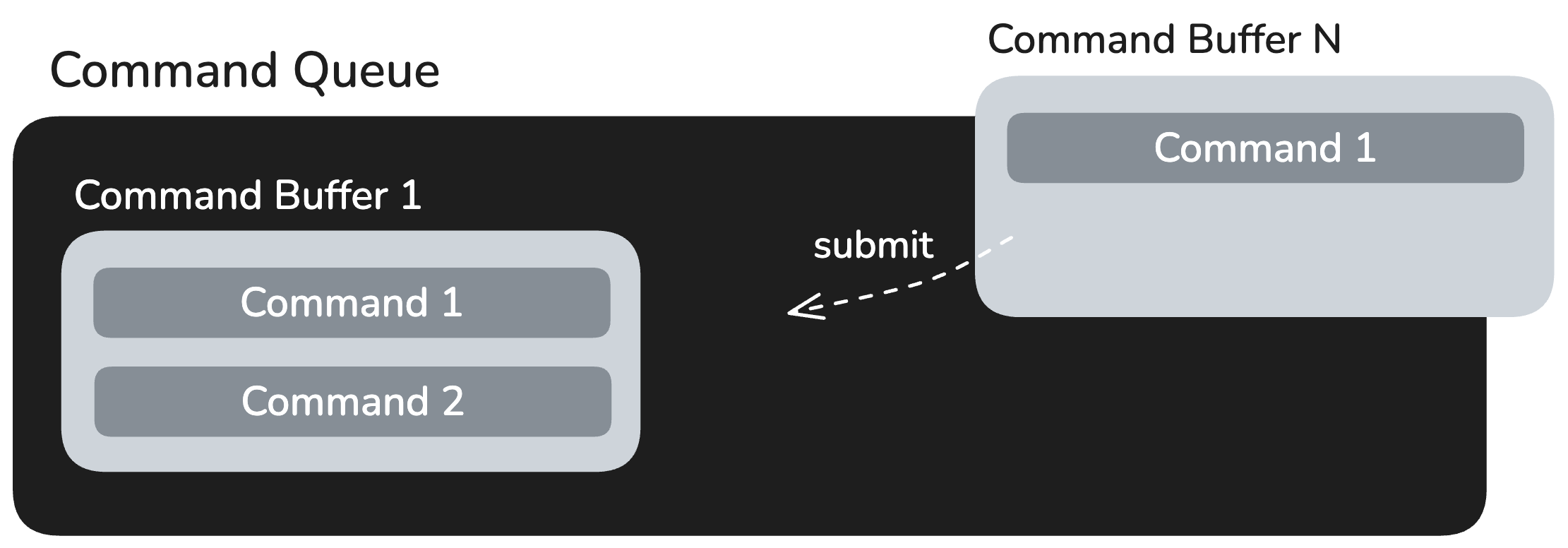
Submission: The command buffers are enqueued into the command queue. This action submits the batch of commands to the UMD, which then forwards them to the KMD for scheduling on the NPU.
-
Execution & Completion: The NPU processes the commands asynchronously. Once a command buffer's execution is complete, the driver signals its completion. The runtime can then query the status of the buffer or use a completion handler to trigger subsequent actions.
-
Reuse/Release: The runtime manages the lifecycle of the buffers, either releasing their resources or reusing them for subsequent inference runs to optimize performance.
Runtime Initialization and Execution¶
Runtime() instance creation¶
When you create a runtime instance, the .rbln file is loaded and the NPU is prepared for inference. This process involves:
-
Memory Allocation: The runtime allocates necessary device memory based on the precomputed layout specified in the
.rblnfile. -
Data Upload: The Command Stream, weights, and other static data are copied from the host to the NPU's memory.
-
Command Buffer Construction & Encoding: As detailed above, the runtime creates command buffers from the uploaded Command Stream and encodes them with specific commands, preparing them for future submission.
-
Device Initialization: Final configuration of the NPU is performed to ensure it is ready for immediate inference execution.
run() method¶
Once the runtime is created, the model is fully prepared to perform inference on the RBLN NPU. When runtime execution is triggered, the RBLN NPU runs inference efficiently using the preconfigured Command Buffers. The process is as follows:
-
Input Preparation: Validate the input tensor provided by the user, perform any required transformations, and prepare the output tensor to receive the results.
-
Data Transfer: Transfer the prepared input tensor to the RBLN NPU using external HDMA.
-
Command Submission: The runtime submits the pre-constructed command buffers to the command queue for execution.
-
Execution: Inference on the RBLN NPU is started by the KMD sequentially invoking the command buffers from the command queue.
-
Result Retrieval: Once all command buffers have finished execution, the KMD signals completion. The final command in the buffer is typically an HDMA transfer command to move the results from the NPU's memory back to the prepared output tensor on the host.
Guidelines for Performance Measurement in Rebellions NPU¶
Methods for Performance Measurement¶
- Using
time.perf_counter_ns()in Python- Example code:
- Advantages
- It is simple to measure end-to-end time.
- Disadvantages
- It is difficult to understand details related to execution.
- Developers cannot see information such as how much time is consumed on the host execution, or how long host-to-device copy takes.
- It is difficult to understand details related to execution.
- Example code:
- Using
get_reports()API- Example and explanation:
get_reports()- This shows the execution time in the Runtime graph. For example, the operations like h2d copy executed on host appear as a single op, and the functions executed on device also appear as a single op.
- Advantages
- This is mainly useful for identifying performance bottlenecks caused by host operations in the overall graph.
- Disadvantages
- As a tool that measures per-op execution time in the Runtime graph, it has the limitation that it does not account for overheads outside of op execution.
- Examples of such overheads include:
- Sanity checks (e.g., input shape, dtype) at the Python level before graph execution (typically microseconds).
- Unavoidable memcpy due to graph topology before graph execution (can take up to milliseconds).
- Terminal output, file I/O, or JSON dump before/after op execution when RUNTIME_TIMER or IODUMP environment variables are set (generally microseconds).
- memcpy when allocating new output tensors for the graph after execution (can take up to milliseconds).
- Examples of such overheads include:
- As a tool that measures per-op execution time in the Runtime graph, it has the limitation that it does not account for overheads outside of op execution.
- Example and explanation:
- Using RBLN Profiler
- Example and explanation
- All individual operations executed on the device are shown as separate ops.
- Advantages
- Easy to analyze performance bottlenecks by visualizing with Perfetto.
- Disadvantages
- Profiling overhead may cause differences from the values measured by methods 1 and 2.
- Provides information about executed ops, but with limitations in understanding what each op represents.
- Users should carefully read the Perfetto analysis guide for interpretation.
- Only visualizes profiling information and does not support exporting data (e.g., CSV). As a result, matching results with the
get_reports()API can require significant effort.
- Example and explanation
- Using torch.profile in vLLM RBLN
- Example
- Advantages
- This provides an overview of overheads occurring throughout vLLM and device execution time at a glance.
- Disadvantages
- Information about what happens inside the device is not visible.
Precautions for Performance Measurement¶
- Perform sufficient warm-up runs before actual measurement.
- Use repeated executions for measurement, and discuss performance with a representative value (e.g., average).
- Large deviations in repeated measurements are usually caused by host-side pre-/post-processing. This can be mitigated by providing enough threads with the
RBLN_NUM_THREADSenvironment variable. - End-to-end model execution on Rebellions NPU consists of:
- Host preprocessing → host-to-device DMA → device compute → device-to-host DMA → host post-processing.
- To measure the duration of each step, use the RBLN profiler.
- Usage and examples are described in the RBLN Profiler guide.
- When running models compiled with
torch.compile, execution time includes all of the above processes.
- Models compiled via
torch.compileoperate synchronously.
get_reports() cautions¶
- Carefully review the
get_reports()documentation. - To enable
get_reports(), set the environment variableRBLN_RUNTIME_TIMER=1. - Enabling this option may slightly slow down inference.
- If
get_reports()is used in warm-up code, the warm-up will be included in the statistics and distort results. To avoid this, explicitly callmodule.flush_reports()after warm-up to clear the data. - Consider the following during measurement:
- After model load, the first one or two executions may show significantly higher device execution times. Subsequent runs usually stabilize.
- Host execution time often fluctuates, showing high variance across runs.