Serving features¶
This page summarizes major vLLM RBLN capabilities supported in Red Hat AI Enterprise (RHAIE) with Rebellions.
OpenAI-compatible API serving¶
vLLM RBLN exposes the same OpenAI-compatible HTTP API as upstream vLLM. Currently /v1/completions and /v1/chat/completions endpoints are fully tested.
Chunked prefill¶
Chunked prefill breaks a long prompt's prefill computation into smaller chunks that can be scheduled alongside decode steps of other requests. This helps reduce latency spikes and improves inter-token latency consistency by preventing a single large prefill from monopolizing device time. For more detail, refer to Chunked Prefill in vLLM.
Chunked prefill is always enabled in vLLM RBLN. vLLM RBLN currently offers limited support for chunked prefill. Mixed scheduling of prefill and decode phases is not yet supported; these operations are processed independently and cannot be interleaved within a single scheduling cycle. These limitations are planned to be addressed in a future release.
Automatic prefix caching¶
Prefix caching improves the efficiency of the LLM engine by eliminating redundant prefill computation. It does this by caching and reusing KV blocks, matched via hash, for shared prompt prefixes across requests. This can reduce time-to-first-token for workloads with repeated prefixes. For more detail, refer to Automatic Prefix Caching.
In vLLM RBLN, automatic prefix caching is always enabled by including --enable-prefix-caching in args of the ServingRuntime. Prefix caching is most effective when long and identical system prompts are reused across many requests, because this increases both compilation reuse and prefix-cache hits in vLLM RBLN. Prefix caching in vLLM RBLN will be improved in the following release.
- Prefix caching in vLLM RBLN is currently optimized for larger block sizes. Improvements for smaller block sizes are planned for a future release.
- Prefix caching in vLLM RBLN currently supports full attention only. Support for additional attention types is planned for a future release.
Structured output¶
Structured output (guided decoding) constrains the model's token generation so that model output follows a specified schema, such as JSON, regex, or grammar, using techniques such as FSM or bitmask-based logit masking. This helps ensure that generated output is always syntactically valid and parseable without post-processing retries. For more detail, refer to Structured Output in vLLM.
vLLM RBLN currently includes tested support for JSON schema, regex, grammar, and structural tag type of fields and formats.
Model parallelism¶
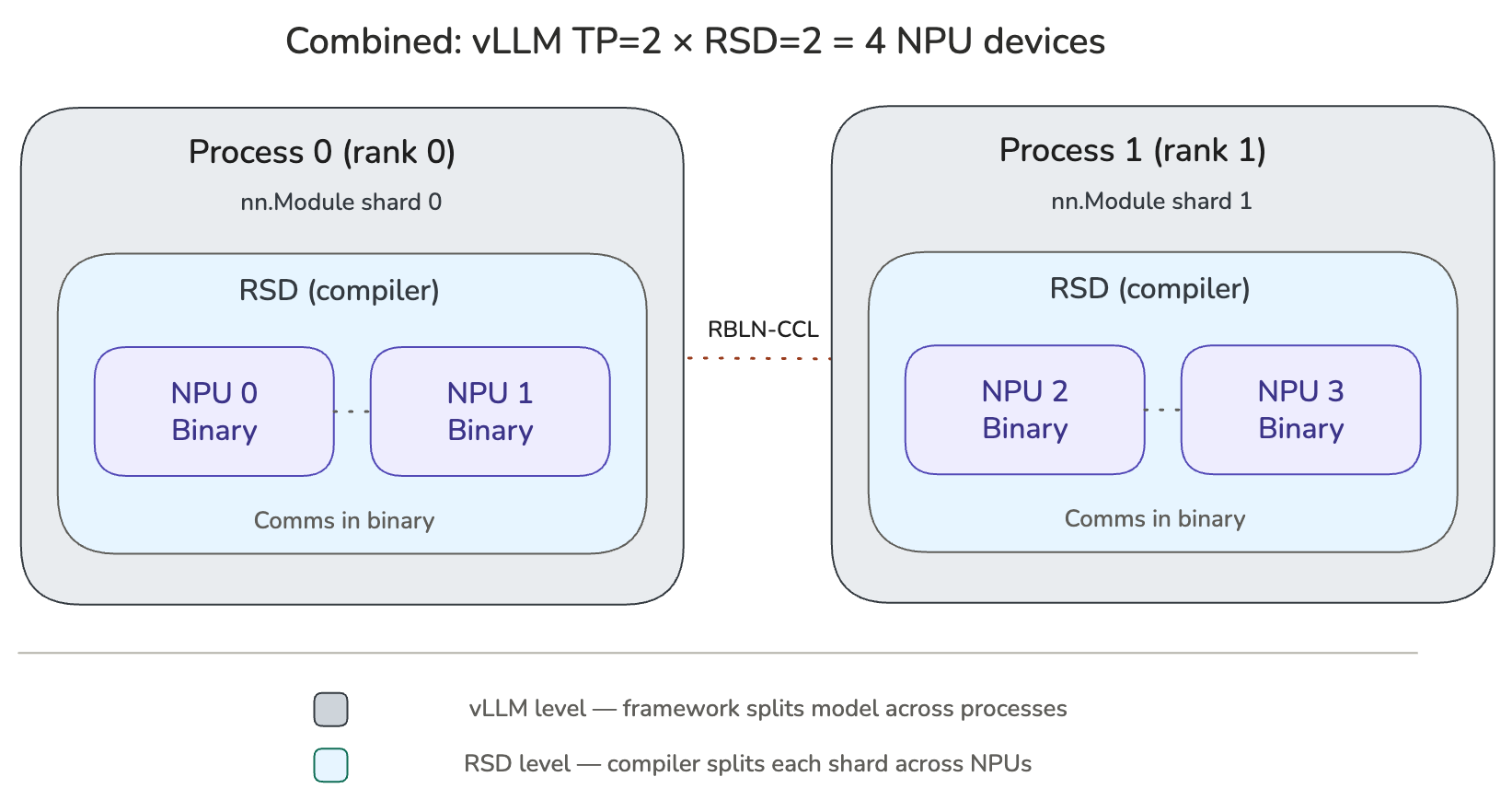
vLLM RBLN supports model parallelism at two levels: Rebellions Scalable Design (RSD) and vLLM-level parallelism (TP, PP, EP). Users can choose either approach independently, or compose both together for additional scaling. When combined, the total device count is the product of both.
RSD overview¶
RSD is a compiler-driven model partitioning strategy unique to RBLN. Rather than requiring the framework to manually split nn.Module layers and insert communication calls at runtime, RSD pushes this complexity into the RBLN compiler. The user provides a whole-model computation graph and specifies how many NPU devices to use. The compiler then automatically analyzes the graph, divides it into per-device shards, and embeds all necessary communication operations directly into the compiled binaries. From the framework's perspective, the result is a single opaque artifact that spans multiple devices — no manual model surgery is required.
RSD-level parallelism¶
With RSD, the user specifies the device count via VLLM_RBLN_NUM_DEVICES_PER_LOCAL_RANK, and the RBLN compiler automatically shards the computation graph and embeds communication operations into the per-device binaries. No module-level splitting is needed at the Python layer.
vLLM-level parallelism¶
With vLLM-level parallelism (TP, PP, EP), the framework splits the model's nn.Module across multiple worker processes, each holding its own shard (e.g., ColumnParallelLinear and RowParallelLinear under TP). The framework is responsible for partitioning weights, inserting collective communication ops, and coordinating across processes. Inter-process communication uses Rebellions Collective Communications Library (RCCL).
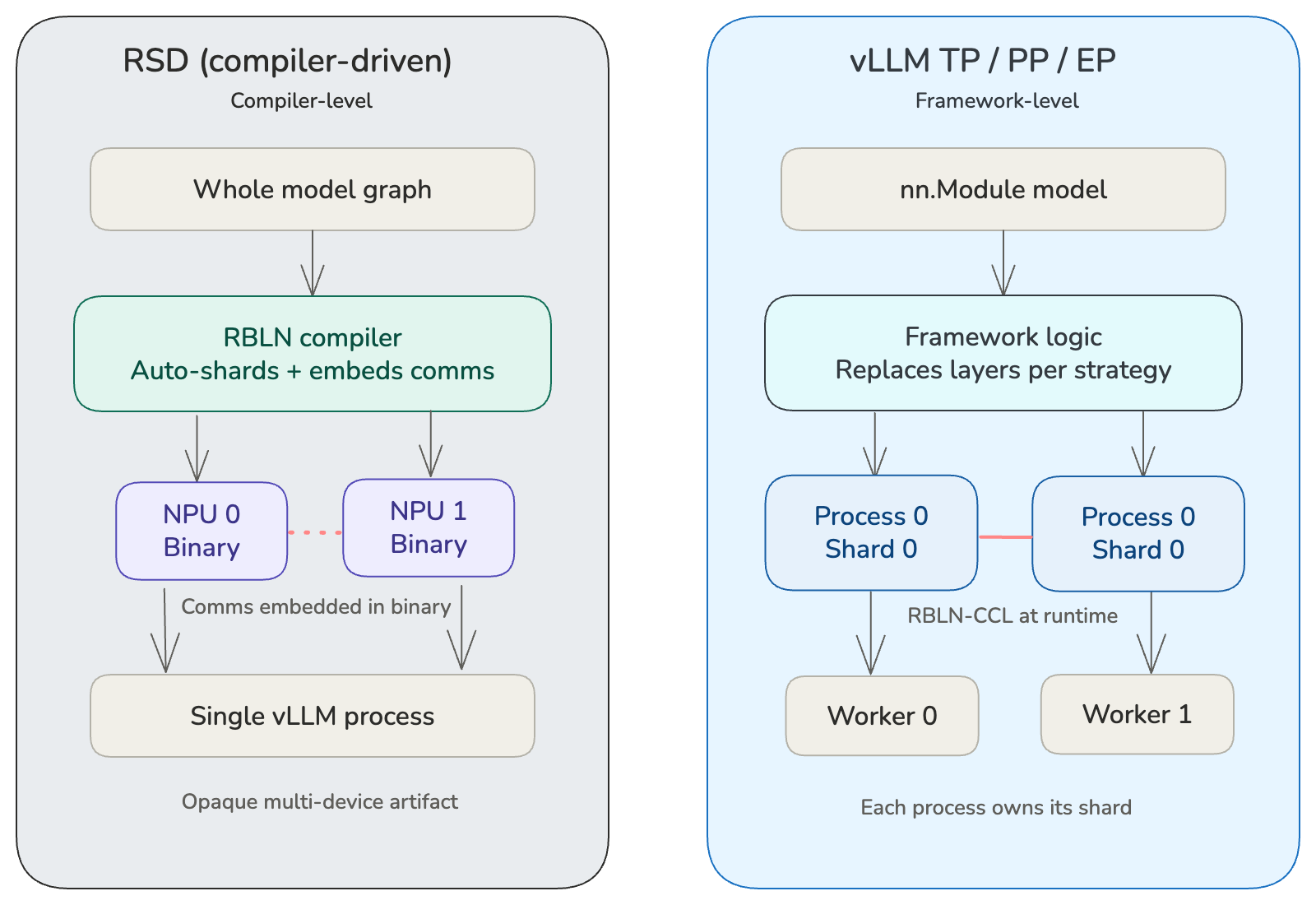
RSD-level vs. vLLM-level parallelism¶
| Feature | RSD level | vLLM level (TP / PP / EP) |
|---|---|---|
| Partitioning | Compiler (graph-level) | Framework (nn.Module-level) |
| Communication | Embedded in device binaries | Handled via RCCL between processes |
| User Config | VLLM_RBLN_NUM_DEVICES_PER_LOCAL_RANK env var |
vLLM parallelism args |
Combined parallelism¶
The two levels are orthogonal and can be used together. RSD splits a model (or model shard) across devices within a single process, while vLLM parallelism splits the model across processes. For example, with vLLM TP=2 and RSD=2, four NPU devices are used: two processes each driving two devices.