서빙 기능¶
이 페이지는 Rebellions와 함께 제공되는 Red Hat AI Enterprise (RHAIE)에서 지원하는 vLLM RBLN의 주요 기능을 요약합니다.
OpenAI 호환 API 서빙¶
vLLM RBLN은 업스트림 vLLM과 동일한 OpenAI 호환 HTTP API를 제공합니다. 현재 /v1/completions 및 /v1/chat/completions 엔드포인트가 검증되었습니다.
Chunked prefill¶
Chunked prefill은 긴 프롬프트의 prefill 계산을 더 작은 청크로 나누어 다른 요청의 decode 단계와 함께 스케줄링할 수 있도록 합니다. 이를 통해 단일 대형 prefill이 디바이스 시간을 독점하는 것을 방지하여 지연 시간 급증을 줄이고 토큰 간 지연(inter-token latency)을 일관되게 만들어 줍니다. 자세한 내용은 Chunked Prefill in vLLM을 참조하십시오.
vLLM RBLN에서는 chunked prefill이 항상 활성화되며, 현재 이 기능은 제한적으로 지원됩니다. prefill 단계와 decode 단계의 혼합 스케줄링은 아직 지원되지 않으며, 두 연산은 단일 스케줄링 사이클 내에서 교차 실행(interleaving)되지 않고 독립적으로 처리됩니다. 이러한 제한은 향후 릴리스에서 개선될 예정입니다.
Automatic prefix caching¶
Prefix caching은 중복 prefill 계산을 제거하여 LLM 엔진 효율을 높입니다. 요청 간에 공유되는 프롬프트 접두사(prefix)에 대해 해시 기반으로 매칭된 KV 블록을 캐시하고 재사용하는 방식으로 동작합니다. 반복되는 접두사가 많은 워크로드에서 첫 토큰까지의 시간(time-to-first-token)을 줄일 수 있습니다. 자세한 내용은 Automatic Prefix Caching을 참조하십시오.
vLLM RBLN에서는 ServingRuntime의 args에 --enable-prefix-caching을 넣어서 automatic prefix caching이 항상 활성화되도록 만듭니다. Prefix caching은 긴 시스템 프롬프트가 많은 요청에서 동일하게 재사용될 때 가장 효과적이며, 이는 vLLM RBLN에서 컴파일 재사용과 prefix-cache hit를 모두 높여줍니다. vLLM RBLN의 prefix caching은 향후 릴리즈에서 추가로 개선될 예정입니다.
- vLLM RBLN의 prefix caching은 현재 큰 block size에서 최적화되어 있습니다. 작은 block size에 대한 개선은 향후 릴리스에서 제공될 예정입니다.
- vLLM RBLN의 prefix caching은 현재 full attention만 지원합니다. 추가 attention 타입 지원은 향후 릴리스에서 제공될 예정입니다.
Structured output¶
Structured output(guided decoding)은 FSM 또는 bitmask 기반 logit masking 같은 기법을 사용해 모델의 토큰 생성을 제약함으로써, JSON/regex/grammar 등 지정된 스키마를 따르는 출력을 생성하도록 합니다. 이를 통해 후처리 재시도 없이도 생성 결과의 문법적 유효성과 파싱 가능성을 높일 수 있습니다. 자세한 내용은 Structured Output in vLLM를 참조하십시오.
vLLM RBLN은 현재 JSON schema, regex, grammar, structural tag 유형의 필드/포맷에 대해 검증된 지원을 제공합니다.
Model parallelism¶
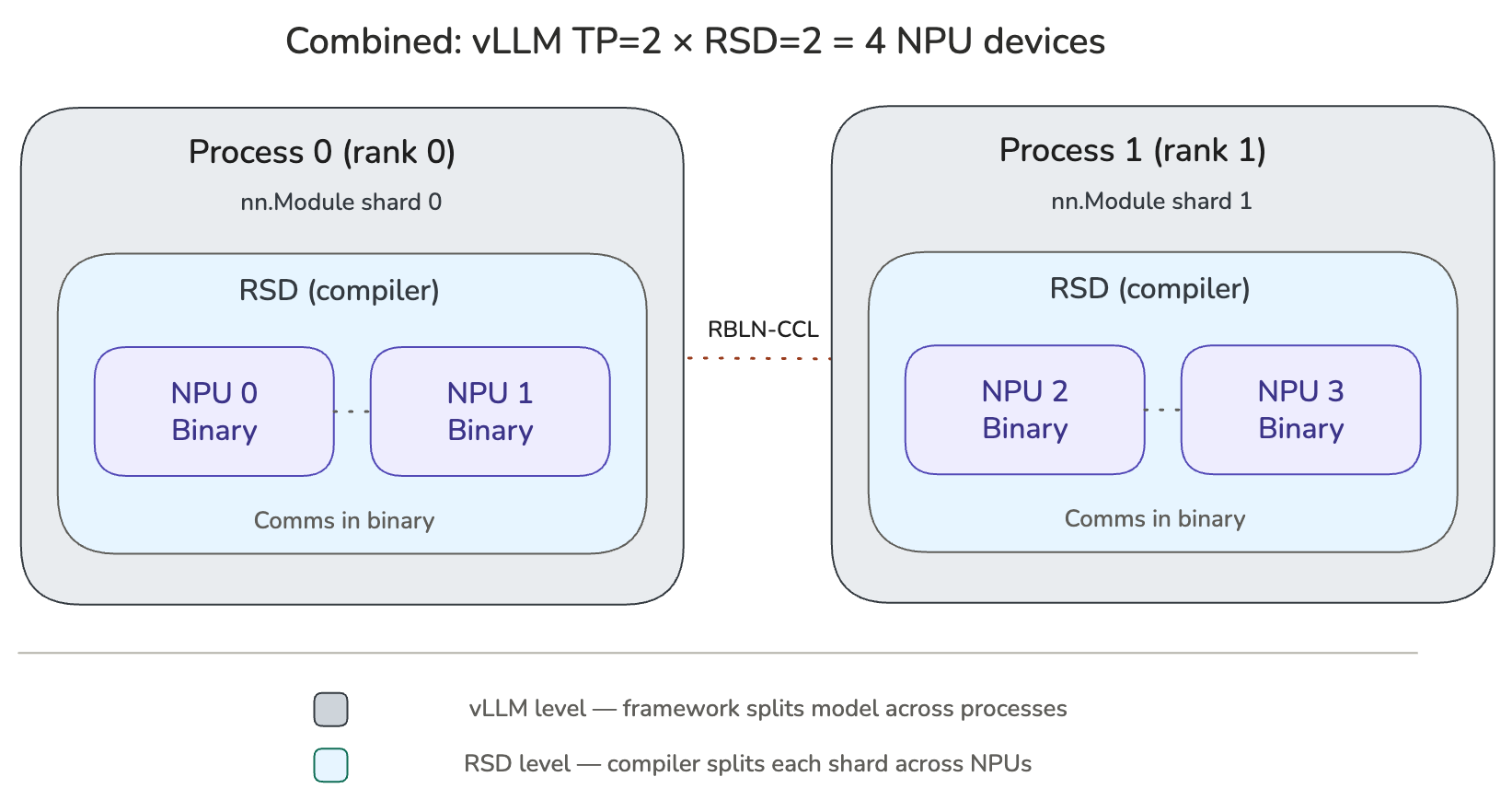
vLLM RBLN은 두 수준의 모델 병렬화를 지원합니다: Rebellions Scalable Design (RSD) 및 vLLM-level parallelism(TP, PP, EP). 사용자는 두 접근 방식을 각각 독립적으로 선택하거나 추가 확장을 위해 함께 조합할 수 있습니다. 함께 사용할 경우 총 디바이스 수는 두 수준의 곱으로 계산됩니다.
RSD 개요¶
RSD는 RBLN에 특화된 컴파일러 기반 모델 분할 기법입니다. 런타임에서 nn.Module 레이어를 수동 분할하고 통신 호출을 삽입하도록 요구하는 대신, RSD는 이러한 복잡성을 RBLN 컴파일러로 이동시킵니다. 사용자는 전체 모델 그래프와 사용할 NPU 디바이스 수만 지정하면 됩니다. 컴파일러는 자동으로 그래프를 분석해 디바이스별로 분할하고, 필요한 모든 통신 연산을 컴파일된 바이너리에 포함시킵니다. 프레임워크 관점에서 결과물은 여러 디바이스를 포괄하는 단일 불투명(opaque) 아티팩트이며, 수동으로 모델을 분해하는 작업이 필요하지 않습니다.
RSD-수준 병렬성¶
RSD에서는 사용자가 VLLM_RBLN_NUM_DEVICES_PER_LOCAL_RANK로 디바이스 수를 지정하면, RBLN 컴파일러가 계산 그래프를 자동으로 샤딩하고 통신 연산을 디바이스별 바이너리에 내장합니다. Python 계층에서 모듈 단위 분할은 필요하지 않습니다.
vLLM-수준 병렬성¶
vLLM-level parallelism(TP, PP, EP)에서는 프레임워크가 모델의 nn.Module을 여러 워커 프로세스로 분할하고, 각 프로세스가 자체 shard를 보유합니다(예: TP의 ColumnParallelLinear, RowParallelLinear). 프레임워크가 가중치 분할, collective communication 연산 삽입, 프로세스 간 조정을 담당합니다. 프로세스 간 통신에는 Rebellions Collective Communications Library (RCCL)이 사용됩니다.
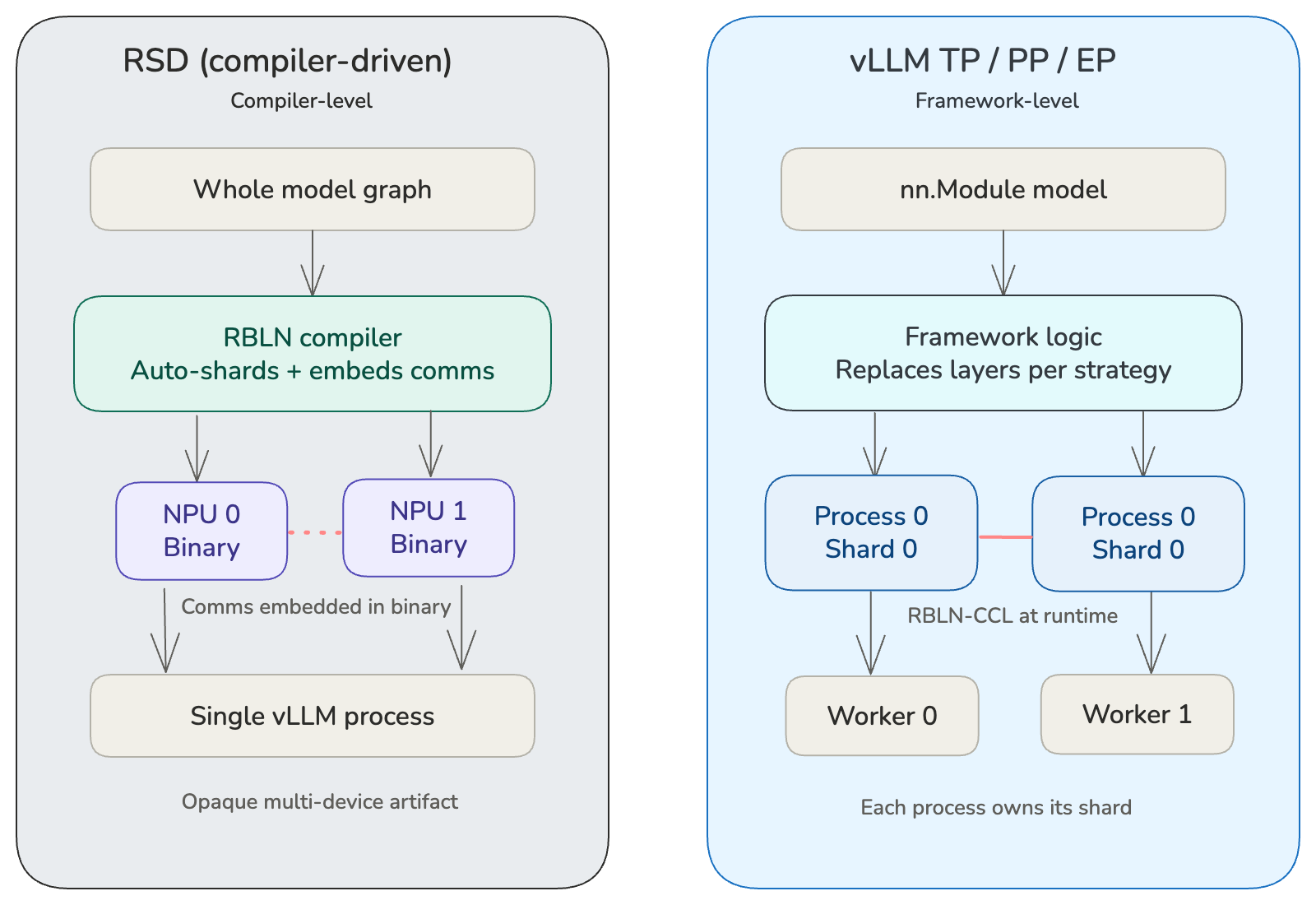
RSD-수준 vs. vLLM-수준 병렬성¶
| Feature | RSD level | vLLM level (TP / PP / EP) |
|---|---|---|
| Partitioning | 컴파일러 (그래프 수준) | 프레임워크 (nn.Module-수준) |
| Communication | 디바이스 바이너리에 포함됨 | 프로세스들 사이에 RCCL을 통해서 이루어짐 |
| User Config | VLLM_RBLN_NUM_DEVICES_PER_LOCAL_RANK 환경 변수 |
vLLM 병렬 파라미터 |
두 병렬성 조합¶
두 병렬성은 서로 무관한 개념이므로 함께 사용할 수 있습니다. RSD는 단일 프로세스 내에서 모델(또는 모델 shard)을 여러 디바이스로 분할하고, vLLM parallelism은 모델을 여러 프로세스로 분할합니다. 예를 들어 vLLM TP=2, RSD=2이면 총 4개의 NPU 디바이스를 사용하며, 각 프로세스가 2개 디바이스를 구동하는 2개 프로세스로 동작합니다.