딥다이브¶
RBLN 런타임의 워크플로우 이해¶
RBLN 런타임은 RBLN NPU에서 컴파일된 모델을 실행하기 위한 API 입니다. 이는 RBLN SDK의 핵심 구성 요소에 대해 직접적이고 단순화된 인터페이스를 제공하며, 설치된 RBLN 드라이버와 직접 상호작용하여 디바이스 실행, 메모리, 동기화 등을 관리합니다. 이를 통해 RBLN SDK 사용자 API를 적용한 애플리케이션과 NPU 하드웨어 간의 효율적인 통신을 보장합니다.
아키텍처
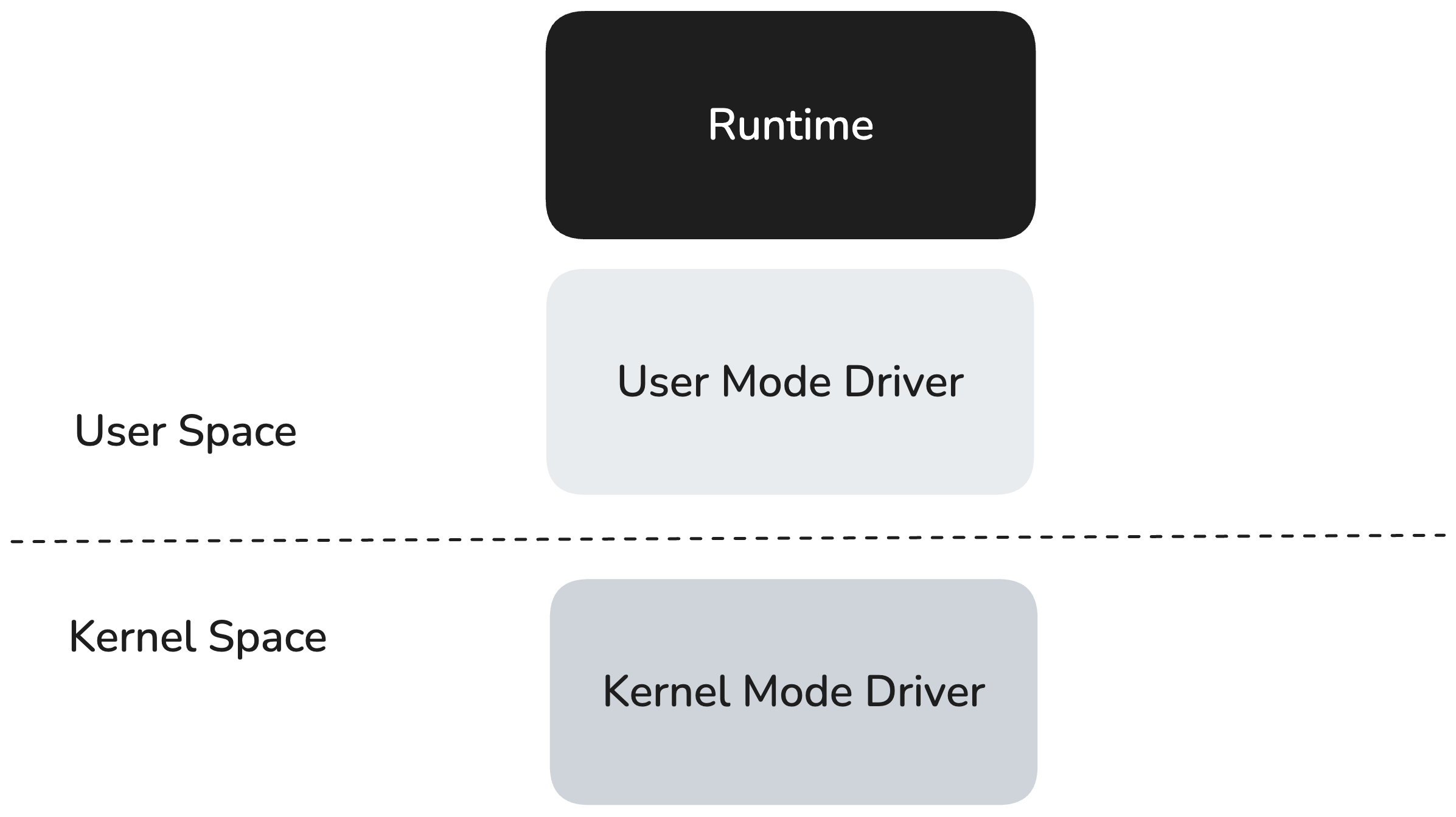
RBLN 런타임은 유저 스페이스에서 동작하며, 유저 모드 드라이버(User Mode Driver, UMD) 위에서 실행되면서, UMD의 저수준 인터페이스를 통해 커널 모드 드라이버(Kernel Mode Driver, KMD)와 통신합니다. KMD는 운영체제의 커널(Kernel)에서 동작하며, 직접적인 하드웨어 접근이나 스케줄링과 같은 Privileged operations를 처리합니다.
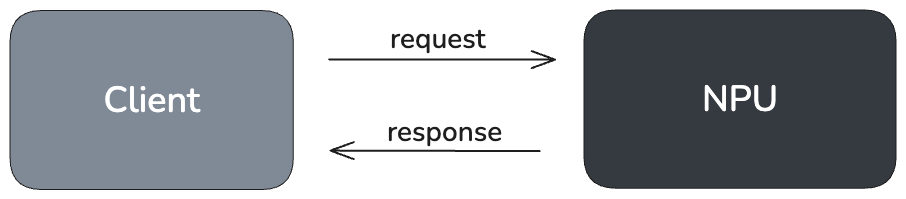
개념적으로, 런타임은 클라이언트–서버 모델을 따릅니다. 호스트 애플리케이션은 클라이언트 역할을 하며, 추론, 메모리 할당, 동기화와 같은 작업을 요청하기 위해 상위 수준 API 호출을 수행합니다. NPU는 서버 역할을 하여 이러한 작업을 실행합니다. 내부적으로 런타임은 호스트의 요청을 저수준 커맨드로 변환하고, 이를 커맨드 버퍼(Command buffer)에 캡슐화한 뒤 RBLN 드라이버에 전달합니다. RBLN 드라이버는 해당 커맨드들을 스케줄링하여 NPU에서 실행되도록 합니다.
RBLN 런타임 워크플로우¶
RBLN 런타임의 추론 워크플로우는 크게 세 단계로 단순화할 수 있습니다:
- 컴파일된 파일 로드:
.rbln파일을 메모리에 로드합니다. - 런타임 인스턴스 생성: rebel.Runtime() 객체의 생성해서 RBLN NPU 기반 추론에 필요한 준비 절차를 수행합니다.
- 추론 실행: module.run() 메서드를 호출해 NPU에서 실행을 트리거합니다.
다음은 RBLN 런타임을 사용하는 간단한 코드 예제입니다:
.rbln 파일 구조¶
컴파일된 .rbln 파일은 NPU에서 신경망을 효율적으로 실행하기 위해 필요한 모든 데이터를 담고 있는 최적화된 컨테이너입니다. 이는 본질적으로 모델을 사전에 패키징하여 즉시 실행할 수 있도록 만든 형태로, 실시간 컴파일(on-the-fly compilation) 과 자원 할당 과정을 제거함으로써 지연 시간을 최소화하고 성능을 극대화하도록 설계되었습니다.
파일의 구성 요소는 크게 모델, 메타데이터, 프로파일 정보 의 세 가지 섹션으로 구분됩니다.
1. 모델(Model)
이 섹션에는 NPU에서 효율적으로 실행될 수 있도록 사전에 최적화된 신경망의 기본 구성 요소들이 포함되어 있습니다.
- 컴파일된 그래프(Compiled Graph): 모델의 연산 흐름을 표현하는 방향성 비순환 그래프(DAG)입니다.
torch.nn.Module과 같은 프레임워크에서 가져온 모델의 원본 그래프는 이 최적화된 형태로 “하향 변환(Lowering)“됩니다. 이를 통해 호스트(CPU)와 NPU 간의 데이터 전송을 포함한 모든 연산이 올바른 위상(Topological) 순서로 실행되어 최대의 효율성을 보장합니다. - 프로그램 바이너리(Program Binary): NPU의 명령어 집합에 맞게 특별히 컴파일된 실행 가능한 기계어 코드입니다. 이는 전통적인 CPU에서 실행 파일처럼, NPU 프로세서가 직접 실행할 수 있는 저수준 연산들을 포함합니다.
- 커맨드 스트림(Command Stream): NPU의 커맨드 프로세서가 처리하는, 가상 주소를 포함한 최적화된 커맨드 시퀀스입니다.
- 메모리 및 I/O(Memory & I/O): 입력, 출력, 중간 데이터 등 모든 텐서에 대한 사전 계산된 메모리 주소와 할당 크기를 포함합니다. 메모리를 사전에 할당함으로써
.rbln파일은 추론 시 동적 메모리 관리에서 발생할 수 있는 성능 병목 현상을 제거합니다. - 가중치(Weights): 모델의 가중치와 바이어스가 고도로 최적화되고 사전 컴파일된 형식으로 저장됩니다. 이를 통해 추가적인 처리나 데이터 변환 없이 NPU 메모리에 직접 로드할 수 있습니다.
Note
대규모 언어 모델(LLM)의 경우, .rbln 파일은 서로 다른 모델 간의 가중치 공유(Weight sharing) 와 같은 고급 최적화를 활용할 수 있습니다. 이를 통해 파일 크기와 메모리 사용량을 크게 줄일 수 있어 배포 효율성이 향상됩니다. 따라서 적용된 최적화 기법에 따라 최종 파일의 크기와 내용은 달라질 수 있습니다.
2. 메타데이터(Metadata)
이 섹션에는 모델의 중요한 구조적 정보와 컴파일 정보가 포함되어 있습니다. 이러한 데이터는 RBLNCompiledModel.inspect() API를 통해 확인할 수 있으며, 이를 통해 모델의 아키텍처와 컴파일 과정의 세부 내용을 파악할 수 있습니다.
3. 프로파일 정보(Profile Info)
이 섹션에는 성능 분석에 필수적인 프로파일링 데이터가 포함되어 있습니다. 이 정보는 개발자가 모델이 NPU에서 어떻게 동작하는지를 이해하고, 잠재적인 병목 구간과 개선할 부분을 식별하는 데 도움을 줍니다.
RBLN 커맨드 구조¶
RBLN 런타임은 그래픽 API가 GPU 작업을 관리하는 방식과 유사하게, RBLN NPU에서 태스크를 오케스트레이션하기 위해 구조화된 저수준 커맨드 시스템을 사용합니다.
커맨드 버퍼 (Command Buffers)¶
커맨드 버퍼는 RBLN 런타임에서 작업을 요청하는 기본 단위입니다. 하나 이상의 커맨드를 캡슐화해서 단일 원자적(Atomic) 태스크로 생성합니다. RBLN 런타임은 커맨드 버퍼를 생성한 뒤, .rbln 파일에 저장된 사전 컴파일된 커맨드 스트림과 Tensor 정보를 이용해 인코딩합니다.
RBLN 커맨드 버퍼의 라이프사이클
- 생성: 런타임 초기화 과정에서 하나 이상의 커맨드 버퍼가 생성됩니다. 각 버퍼는 모델 실행 흐름의 논리적 단위를 나타냅니다.
- 인코딩: 런타임은 각 버퍼에 구체적인 커맨드를 채웁니다. 여기에는 텐서 전송(HDMA), 연산 커널 디스패치, 동기화 지점(Barrier) 등이 포함되며, 이는 전체 추론 과정을 수행하는 데 필요합니다.
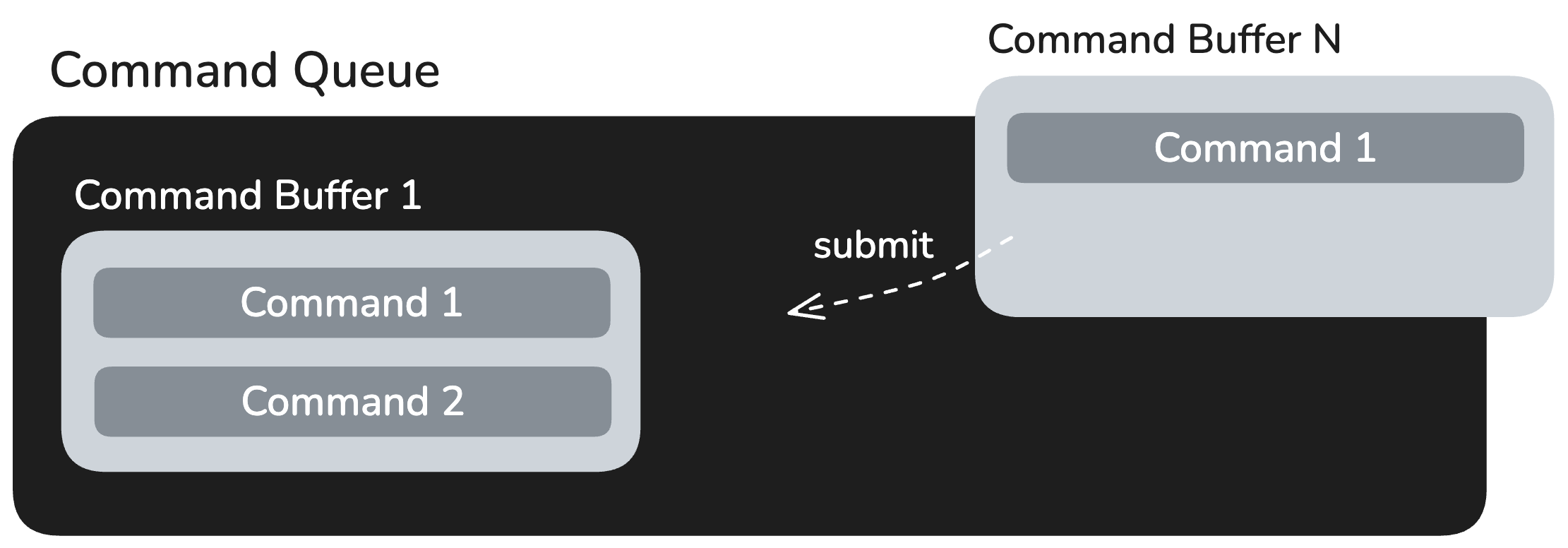
- 제출: 커맨드 버퍼는 커맨드 큐에 Enqueue됩니다. 이 동작은 커맨드 집합을 UMD에 전송되는 것을 의미하며, 이후 UMD는 이를 KMD에 전달하여 NPU에서 스케줄링이 이루어지도록 합니다.
- 실행 및 완료: NPU는 커맨드를 비동기적으로 처리합니다. 커맨드 버퍼의 실행이 완료되면 드라이버가 완료 신호를 보냅니다. 이후 런타임은 버퍼의 상태를 조회하거나 완료 핸들러를 사용해 후속 작업을 트리거할 수 있습니다.
- 재사용/해제: 런타임은 버퍼의 라이프사이클을 관리하며, 리소스를 해제하거나 이후 추론 실행에서 재사용하여 성능을 최적화합니다.
런타임 초기화 및 실행¶
Runtime() 인스턴스 생성¶
런타임 인스턴스를 생성하면 .rbln 파일이 로드되고 NPU가 추론을 수행할 준비가 됩니다. 이 과정에는 다음 단계들이 포함됩니다:
- 메모리 할당:
.rbln파일에 지정된 사전 계산된 레이아웃에 따라 런타임이 필요한 디바이스 메모리를 할당합니다. - 데이터 업로드: 커맨드 스트림, 가중치, 기타 정적 데이터가 호스트에서 NPU의 메모리로 복사됩니다.
- 커맨드 버퍼 생성 및 인코딩: 앞서 설명한 대로, 런타임은 업로드된 커맨드 스트림을 기반으로 커맨드 버퍼를 생성하고 구체적인 커맨드로 인코딩하여 이후 제출을 준비합니다.
- 디바이스 초기화 : NPU가 즉시 추론을 실행할 수 있도록 최종 설정을 수행합니다.
run() 메서드¶
런타임이 생성되면, 모델은 RBLN NPU에서 추론을 수행할 준비가 완료됩니다. 런타임 실행이 트리거되면 RBLN NPU는 사전에 구성된 커맨드 버퍼를 활용하여 효율적으로 추론을 수행합니다. 과정은 다음과 같습니다:
- 입력 준비: 사용자가 제공한 입력 텐서를 검증하고, 필요한 변환을 수행한 뒤 결과를 받을 출력 텐서를 준비합니다.
- 데이터 전송: 준비된 입력 텐서를 외부 HDMA를 사용하여 RBLN NPU로 전송합니다.
- 커맨드 제출: 런타임은 사전에 생성된 커맨드 버퍼를 커맨드 큐에 Enqueue하여 실행을 요청합니다.
- 실행: KMD는 커맨드 큐에서 커맨드 버퍼를 순차적으로 호출하여 RBLN NPU에서 추론을 시작합니다.
- 결과 수신: 모든 커맨드 버퍼의 실행이 완료되면 KMD가 완료 신호를 보냅니다. 버퍼의 마지막 커맨드는 보통 HDMA 전송 커맨드이며, 이를 통해 NPU 메모리에 저장된 결과가 호스트의 준비된 출력 텐서로 이동합니다.
RBLN NPU에서 성능 측정을 위한 가이드라인¶
성능 측정을 위한 방법들¶
- python에서
time.perf_counter_ns()를 사용하는 방법- 예제 코드:
- 장점
- end to end 시간을 간단하게 측정할 수 있습니다.
- 단점
- 실행에 관련된 detail을 파악하기 어렵습니다.
- host에서 실행되는 부분이 얼마나 있는지, host to device copy가 얼마나 걸리는지와 같은 정보들은 볼 수 없습니다.
- 예제 코드:
get_reports()API를 사용하는 방법- 예시 및 설명:
get_reports()- Runtime graph에서의 실행시간을 보여줍니다. 여기에서는 host에서 실행되는 h2d copy등이 하나의 op으로 보이고 디바이스에서 실행되는 함수도 하나의 op으로 보입니다.
- 장점
- 주로 전체 graph에서 host op이 병목이 되는 경우 어떤 host op이 범인인지 찾는데 유용합니다.
- 단점
- Runtime graph에서 op당 실행시간을 측정해 주는 도구로서 runtime graph에서 각 op execution 이외의 overhead는 잡히지 않는 한계가 있습니다.
- op execution 이외의 overhead의 예
- python level에서 graph를 실행하기 전에 input에 대한 shape, dtype등의 sanity check (us 단위로 걸립니다)
- graph 실행하기 전에 graph의 topology상으로 불가피한 memcpy (ms 단위까지 걸릴 수 있습니다)
- RUNTIME_TIMER 또는 IODUMP 환경변수가 설정되는 경우, op 실행 전후에 터미널 출력이나 파일입출력, 또는 json dump등에 걸리는 시간 (대체로 us 단위로 걸립니다)
- graph 실행 후 graph의 output tensor를 새로 할당하는 경우의 memcpy (ms 단위까지 걸릴 수 있습니다)
- op execution 이외의 overhead의 예
- Runtime graph에서 op당 실행시간을 측정해 주는 도구로서 runtime graph에서 각 op execution 이외의 overhead는 잡히지 않는 한계가 있습니다.
- 예시 및 설명:
- RBLN Profiler를 사용하는 방법
- 예시 및 설명
- 디바이스에서 실행되는 모든 개별 연산이 각각의 op으로 보이도록 되어 있습니다.
- 장점
- Perfetto를 사용해서 visual하게 볼 수 있어서 병목 현상의 분석이 용이합니다.
- 단점
- Profile 오버헤드가 있어서 1번 방법과 2번 방법으로 측정된 값과 차이가 있습니다.
- 실행된 op에 대한 정보가 나오나 이것이 어떤 op인지 이해하는데 한계가 있습니다.
- 일단 Perfetto 분석 가이드를 자세히 읽어봐야 합니다.
- Profiling 정보를 visualize만 하고 csv등으로 자료를 뽑아주는 기능은 없어서 get_reports API에서 본 것과 일치시키는데 수고가 많이 듭니다.
- 예시 및 설명
- vLLM RBLN에서 torch.profile 사용하는 방법
- 예시
- 장점:
- vllm 전체에 걸쳐 발생하는 오버헤드와 디바이스 실행시간을 한눈에 훑어볼 수 있습니다.
- 단점:
- 디바이스 내부에서 일어나는 일의 정보는 보이지 않습니다.
성능 측정시 유의사항¶
- 실제 측정 전에 warm up을 위한 실행을 충분히 해줍니다.
- 실제 측정값은 반복해서 실행한 뒤에 측정된 모든 값의 대표값(예를 들어 평균)으로 표현합니다.
- 반복 측정 시에 측정값에 편차가 많이 생길 경우 대부분은 host preprocessing/post processing에서 편차가 생기는 경우가 많습니다.
RBLN_NUM_THREADS환경 변수를 사용해서 thread 수를 충분히 주면 이 편차가 줄어듭니다. - 리벨리온 NPU의 end to end 모델 연산은 다음과 같은 것으로 구성되어 있습니다.
- host preprocessing -> host-to-device DMA -> device compute -> device-to-host DMA -> host post-processing
- 각 단계에서 실행시간을 측정하려면 RBLN Profiler를 사용해야 합니다.
- 사용법과 예제는 RBLN Profiler 가이드에 있습니다.
torch.compile로 컴파일한 뒤에 실행하면 실행시간에는 위의 모든 과정이 포함됩니다.
torch.compile을 통해서 compile된 모델은 sync로 동작합니다.
get_reports() 주의점¶
- 사용자들은
get_reports()문서를 주의깊게 읽어봐야 합니다. - 위의
get_reports()함수를 쓰려면RBLN_RUNTIME_TIMER=1을 줘야 합니다. - 이것을 켜면 inference가 조금 느려질 수 있습니다.
- Warm-up을 하는 코드에서 get_reports를 사용할 경우 warm-up까지 통계에 포함되기 때문에 결과에 왜곡이 생길 수 있습니다. 따라서 warm-up이 끝난 이후에 명시적으로
module.flush_reports()를 호출하면 warm-up으로 인한 결과는 통계에 포함되지 않게 됩니다. - 측정 시에 다음의 상황을 고려해야 합니다.
- 보통 모델 load하고 첫 한 두번 정도는 디바이스에서 수행 시간이 크게 나오고, 그 이후에 계속 반복하면 비교적 일정한 수행시간이 나옵니다.
- host에서 걸리는 시간은 자주 커졌다 작아졌다 합니다. (수행시간의 변동이 많이 있음)