설치¶
이 절에서는 Red Hat AI Enterprise with Rebellions를 위한 소프트웨어 스택의 설치 및 검증 방법을 설명합니다. 다음 순서대로 구성 요소를 설치하고 검증을 수행하십시오.
-
Red Hat OpenShift 클러스터 — 클러스터 설치 및 라이프사이클 작업은 OpenShift 지원을 참조하십시오.
-
RBLN NPU Operator — 클러스터 준비가 완료되면 오퍼레이터를 설치합니다. 이 오퍼레이터는 OpenShift에서 RBLN NPU를 프로비저닝하는 데 필요한 Rebellions 구성 요소를 배포하고 관리합니다. RBLN NPU Operator를 참조하십시오.
-
검증 — 오퍼레이터가 실행되면 Rebellions NPU 디바이스가 클러스터 워크로드에 노출됩니다. 아래 점검을 수행하여 리소스 등록, 파드 스케줄링, 컨테이너 내부 디바이스 접근을 확인하십시오.
-
노드 capacity 조회(리소스 등록)
노드 capacity를 조회합니다(예시):
등록이 정상적으로 완료되면 JSON에 다음과 같이
rebellions.ai/npu항목이 포함됩니다.이 항목은 해당 노드가 가속기를 광고(advertise)하고
rebellions.ai/npu을 요청하는 파드를 스케줄할 수 있음을 의미합니다. -
파드 내부 디바이스 가시성
ATOM™ 가속기를 사용하려면 파드 명세에서 requests와 limits 모두에
rebellions.ai/npu을 선언해야 합니다. 예:스케줄러가 디바이스를 노출하는 노드에 파드를 바인딩할 수 있도록 requests와 limits를 동일하게 설정하십시오.
실행 중인 파드에서 다음 명령을 실행합니다.
예상 출력에는 디바이스 식별자, 메모리, 사용률 정보가 포함되며, 이는 컨테이너가 ATOM™ 가속기에 접근 가능함을 확인해 줍니다.
참조:
rbln-smi출력 예시> rbln-smi +-------------------------------------------------------------------------------------------------+ | Device Information KMD ver: 3.2.2 | +-----+-----------+---------+---------------+------+---------+------+---------------------+-------+ | NPU | Name | Device | PCI BUS ID | Temp | Power | Perf | Memory(used/total) | Util | +=====+===========+=========+===============+======+=========+======+=====================+=======+ | 0 | RBLN-CA25 | rbln0 | 0000:05:00.0 | 36C | 56.4W | P14 | 0.0B / 15.7GiB | 0.0 | +-----+-----------+---------+---------------+------+---------+------+---------------------+-------+ | Context Information | +-----+---------------------+--------------+-----------+----------+------+---------------+--------+ | NPU | Process | PID | CTX | Priority | PTID | Memalloc | Status | +=====+=====================+==============+===========+==========+======+===============+========+ | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | +-----+---------------------+--------------+-----------+----------+------+---------------+--------+ rbln-smi success, skipping rbln-stat
점검에 실패하거나 명령 출력이 위 패턴(샘플
rbln-smi목록 포함)과 본질적으로 다를 경우 고객 지원으로 문의하십시오. -
-
Red Hat OpenShift AI — Red Hat OpenShift AI self-managed 설치 가이드의 절차에 따라 제품을 설치합니다.
Red Hat AI Enterprise with Rebellions NPU는 Red Hat OpenShift AI 3.4에서 검증되었으며, 이 버전은 KServe 지향 모델 서빙 워크플로, 하드웨어 프로파일, 런타임 자동 선택 기능을 제공하여 배포를 의도한 컴퓨트 리소스에 맞게 구성할 수 있습니다.
핵심 구성 요소와 역할¶
Red Hat OpenShift AI 3.4의 모델 서빙은 다음 두 가지 주요 커스텀 리소스에 의존합니다.
- ServingRuntime — 추론 스택을 위한 컨테이너 이미지, 엔트리포인트, 환경 변수, 지원 모델 포맷
- HardwareProfile — 스케줄러가 적절한 노드에 워크로드를 배치할 수 있도록 CPU, 메모리, 가속기, toleration, node-selector 제약을 정의
Rebellions는 이 워크플로를 따르는 RBLN
ServingRuntime, RBLNHardwareProfile오브젝트용 레퍼런스 매니페스트를 제공합니다.RBLN ServingRuntime¶
ServingRuntime은 모델 서빙 파드가 어떻게 구성되는지를 정의합니다. 즉, 어떤 이미지를 실행할지, 모델을 어떻게 제공할지, 어떤 프로토콜과 포맷을 지원할지를 지정합니다. 대시보드의 Settings > Model resources and operations > Serving runtimes에서 등록한 뒤 Add serving runtime을 선택하십시오. 다음과 같은 대화상자가 표시됩니다.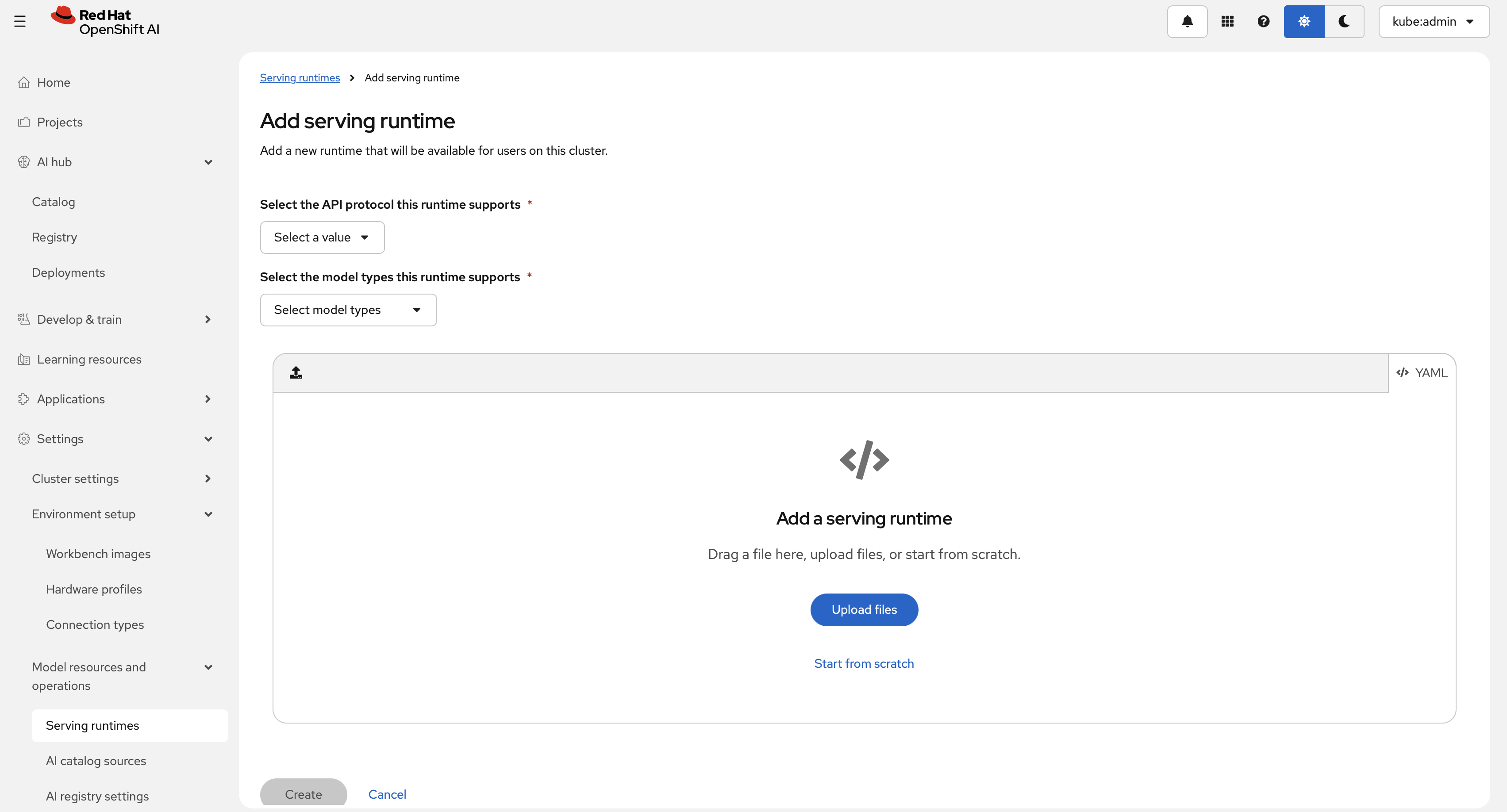
API 프로토콜(REST 또는 gRPC)을 선택합니다. 이 예시에서는 REST와 생성형 모델 타입을 사용합니다. 아래
ServingRuntimeYAML을 에디터에 붙여 넣으십시오.위
ServingRuntime에는 이미지를 다운로드 (Pull) 받을 때 필요한 시크릿이 포함되어 있지 않습니다. OpenShift의 글로벌 풀 시크릿을 사용하거나 다음과 같이ServingRuntime에 별도의 시크릿을 생성하여 사용할 수 있습니다.위 YAML은 다음 명령으로 적용할 수 있습니다.
RBLN Hardware profile¶
하드웨어 프로파일은 타겟 스케줄링을 위한 커스텀 리소스입니다. 워크벤치 및 모델 서빙 같은 워크로드에 대해 CPU, 메모리, 가속기, toleration, node-selector 요구 사항을 선언하는 데 사용합니다. Settings > Environment setup > Hardware profiles에서 RBLN 프로파일을 생성한 뒤 Create hardware profile을 선택하십시오.
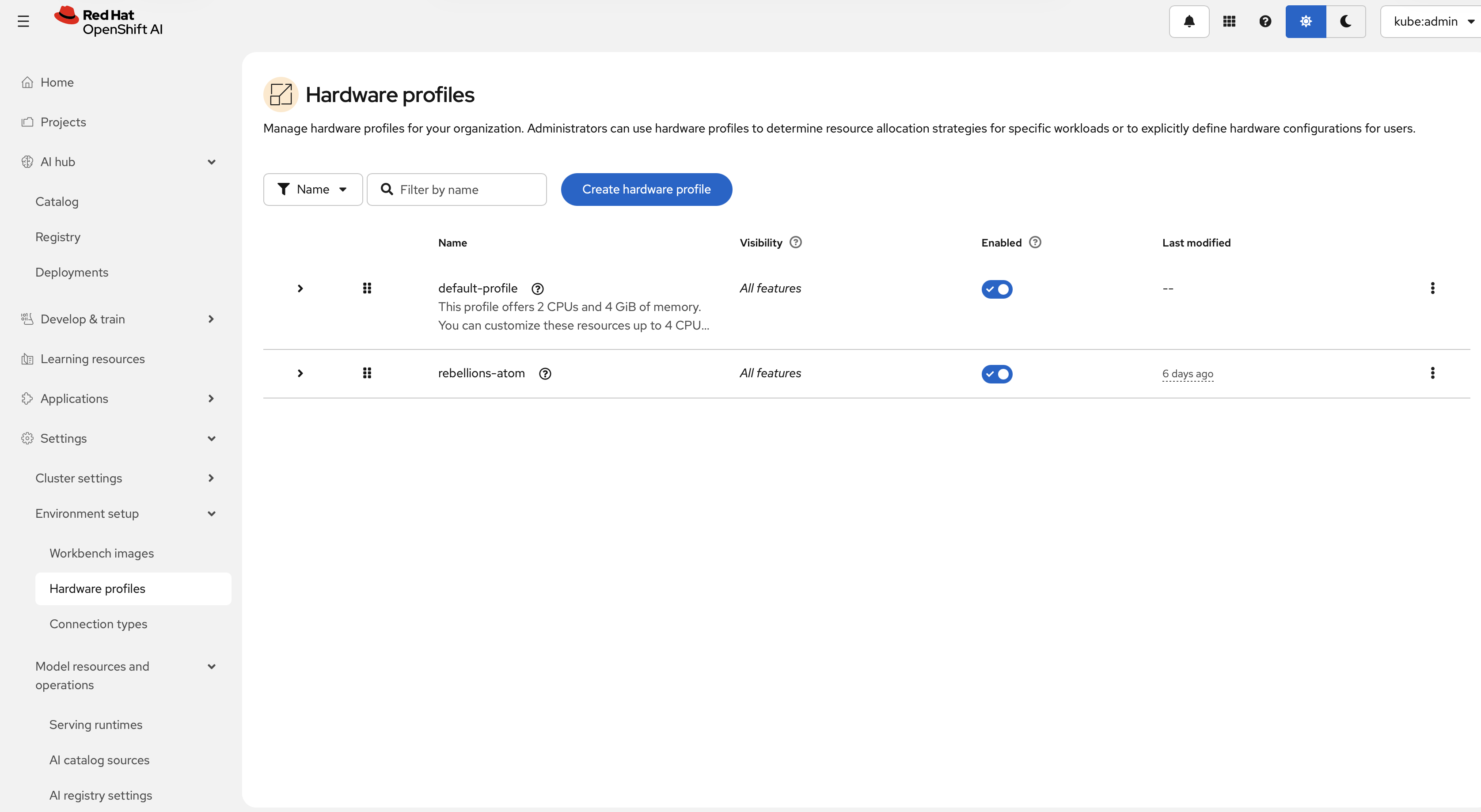
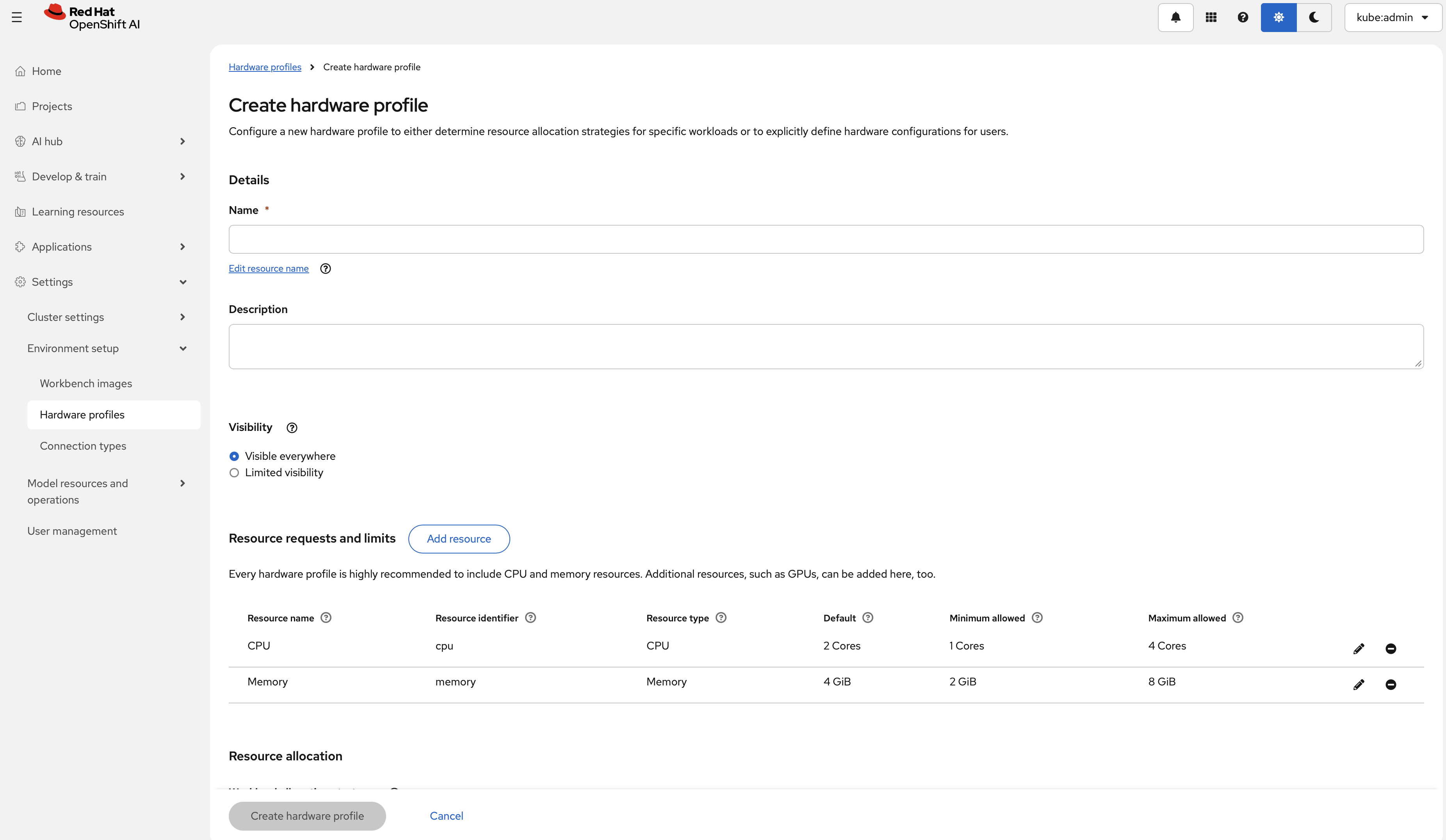
폼에서 다음 항목을 설정할 수 있습니다.
- 하드웨어 식별자
- 명시적 리소스 제한(CPU, 메모리, 가속기)
- Tolerations
- Node selectors
다음은 리벨리온 NPU인 ATOM™-MAX(RBLN-CA25)를 위한 권장 RBLN 하드웨어 프로파일입니다.
위 YAML은 다음 명령으로 적용할 수 있습니다.
자세한 내용은 Red Hat 가이드 Working with hardware profiles를 참조하십시오.
-
로컬 테스트(Podman 또는 Docker) - OpenShift에서 모델 서빙을 배포하기 전에 호스트에서 RHOAI vLLM RBLN 이미지의 컨테이너 인스턴스가 정상적으로 생성되는지 확인합니다. 또한 Kubernetes 파드에 배포하기 전에 AI 모델이 동작하는지 사전 점검할 수 있습니다. 아래 단계를 따르십시오.
-
레지스트리 로그인
컨테이너 레지스트리에 인증합니다.
-
컨테이너 실행
-
테스트 요청 전송 샘플 chat completion 요청을 전송합니다.
로컬 검증이 성공하면 Red Hat OpenShift AI에서 모델 배포 및 추론 단계로 진행하십시오.
-