모델 배포¶
모델 배포는 모델 서빙을 준비하는 작업입니다. 모델을 배포하기 전에 OpenShift AI 대시보드의 Settings에서 필요한 RBLN ServingRuntime과 HardwareProfile이 등록되어 있는지 확인하십시오.
-
프로젝트 생성
- 좌측 메뉴에서 Projects를 클릭한 뒤 Create project를 선택합니다.
- 이름과 설명을 입력하고 확인합니다. 이후 생성되는 모든 리소스(연결, 배포, 권한)는 이 프로젝트 범위로 관리됩니다.
-
스토리지 준비 및 데이터 연결 생성
- 모델 아티팩트를 위한 스토리지 백엔드를 준비합니다. 지원되는 옵션에는 S3 호환 오브젝트 스토어, URI 기반 저장소, PersistentVolumeClaim(PVC)이 포함됩니다.
- 프로젝트 내부에서 Connections 탭을 열고 Create connection을 선택합니다.
- 스토리지 백엔드에 맞는 연결 유형(예: S3-compatible object storage 또는 URI - v1)을 선택하고 필수 항목을 입력한 뒤 저장합니다.
-
배포 마법사 열기
프로젝트 내부에서 Deployment 탭을 열고 Deploy model을 선택합니다. 그러면 Deploy a model 마법사가 열립니다.
-
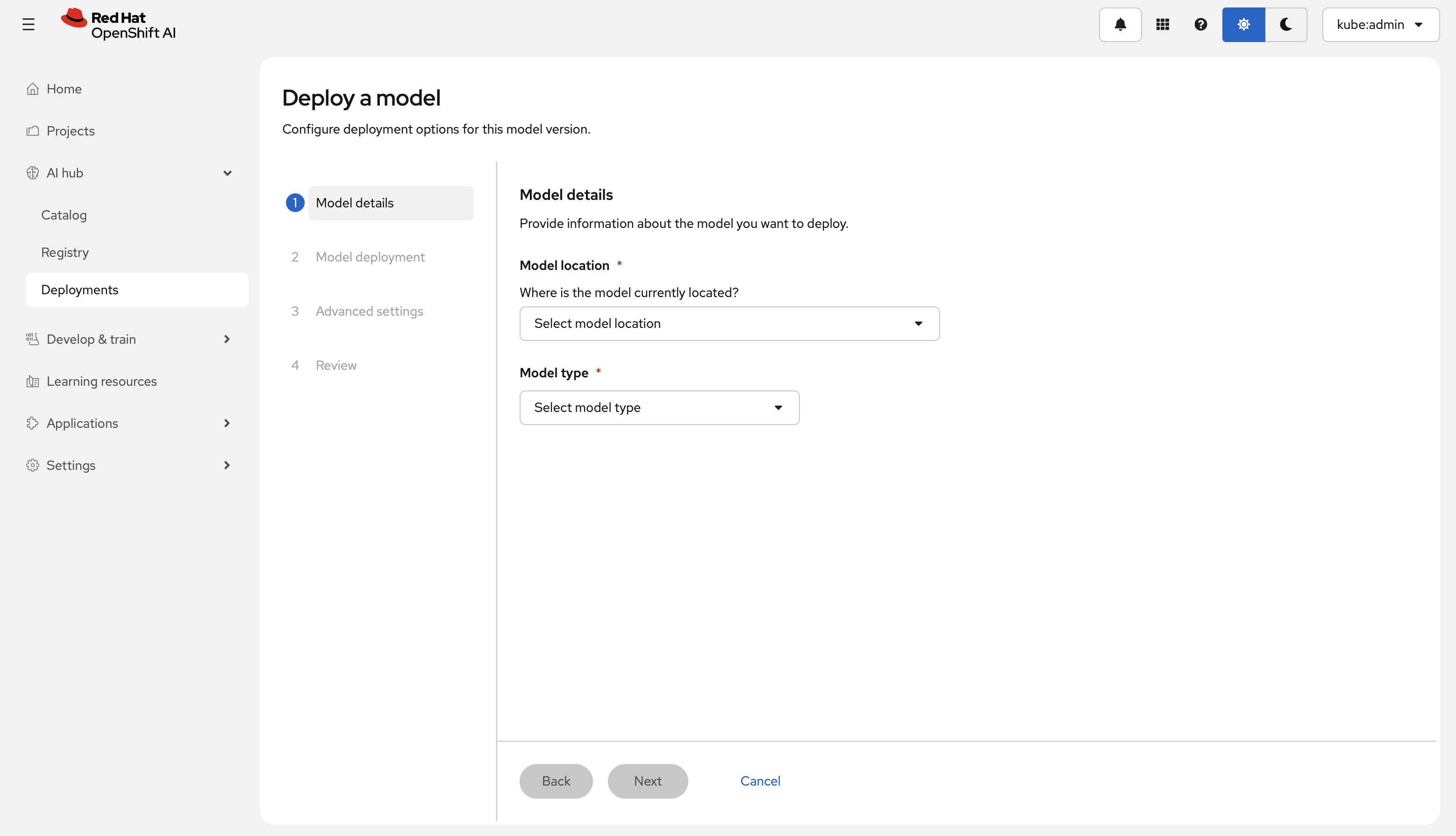
Step 1 — Model details
- Model location에서 Existing connection을 선택하고 2단계에서 생성한 연결을 선택합니다.
- Model type을 선택합니다: 고전적인 ML 모델은 Predictive AI, 대규모 언어 모델(LLM)은 Generative AI를 선택합니다.
-
Step 2 — Model deployment settings
- Model deployment name: 배포를 식별할 고유 이름을 입력합니다.
- Hardware profile: 대상 하드웨어(예: Rebellions NPU 프로파일)에 맞는 프로파일을 선택하고 가속기 수를 지정합니다.
- Serving runtime: 하드웨어와 모델 포맷에 맞게 구성한 커스텀 런타임을 선택합니다.
-
Step 3 — Advanced settings
- 외부 추론 엔드포인트를 노출하려면 Model route를 활성화합니다. 필요 시 Token authentication을 활성화하여 엔드포인트 접근을 제한할 수 있습니다.
- Configuration parameters 섹션에서 선택한 서빙 런타임에 필요한 런타임 인자 또는 환경 변수를 추가합니다. 이 설정은 현재 배포에만 적용되며 전역 런타임 설정에는 영향을 주지 않습니다.
배포 마법사는 내부적으로 Red Hat OpenShift AI의 KServe용 InferenceService 커스텀 리소스(CR)를 생성합니다. 생성 후 KServe 컨트롤러가 이를 감지하고 모델 서빙에 필요한 Deployment, Service, Pod 등의 리소스를 자동으로 생성합니다. InferenceService는 아래에서 자세히 설명합니다.
-
-
배포 및 검증
- Deploy를 선택해 배포를 제출합니다.
- Deployments 탭에서 상태를 모니터링합니다. 상태가 Available이 되면 Inference endpoints 열에 추론 엔드포인트 URL이 표시됩니다.
- 필요 시 OpenShift 콘솔에서 파드 터미널을 열고
rbln-smi를 실행해 서빙 컨테이너 내부에서 Rebellions NPU가 인식되는지 확인합니다.
InferenceService¶
InferenceService는 모델 서빙 배포를 정의합니다. 선택한 런타임으로 요청을 라우팅하고, 구성된 하드웨어 프로파일을 적용하며, REST 또는 gRPC 엔드포인트를 노출합니다. 일반적으로 다음을 지정합니다.
- 모델 위치 및 포맷
- 사용할
ServingRuntime - 적용할
HardwareProfile - REST 또는 gRPC에 대해 passthrough 라우팅 활성화 여부
- 배포된 모델의 HTTP 또는 gRPC 접근 설정
InferenceService를 생성하는 방법은 두 가지입니다.
- OpenShift AI UI 사용: Project에서 Deployment 탭을 열고 Deploy a model을 선택하면 마법사가
InferenceServiceCR을 자동으로 생성합니다. - YAML 사용: 매니페스트를 직접 적용합니다.
다음 예시는 vLLM 기반 런타임으로 Qwen3 모델을 배포하는 RBLN InferenceService입니다.
InferenceService CR이 배포된 이후, 정상 응답 여부를 다음과 같이 확인할 수 있습니다.
참고 사항¶
- vLLM RBLN의 모델 서빙에는 컴파일 및 워밍업이 필요합니다. 이 과정은 첫 요청 처리 시(예:
LLM(...)초기화 시) 엔진 시작 단계에서 자동 수행됩니다. - 초기 시작은 그래프 컴파일 및 워밍업이 수행되므로 더 오래 걸립니다.
- 이후 실행에서는 기본적으로 캐시된 바이너리를 재사용합니다(
$VLLM_CACHE_ROOT/rbln, 일반적으로~/.cache/vllm/rbln). - 모델 또는 런타임 shape 파라미터(예:
max_num_seqs,max_num_batched_tokens,block_size)를 변경하면 추가 컴파일이 발생할 수 있습니다.