프로파일링 가이드¶
vLLM RBLN의 성능을 최적화하기 위해서는 기본 메트릭인 TTFT(Time To First Token)와 TPOT(Time Per Output Token) 외에도, RBLN NPU의 동작을 심층적으로 분석할 수 있는 저수준(Low-level) 프로파일링이 필요합니다.
본 문서에서는 PyTorch-Level Profiler와 RBLN Profiler라는 두 가지 방식의 프로파일링 가이드를 제공합니다.
1. Pytorch-Level Profiler¶
PyTorch 프로파일러를 활용하여 연산 단위의 성능을 측정하는 방법입니다. 이를 통해 커널(Kernel) 실행 시간과 연산 병목 구간을 분석할 수 있습니다. vLLM RBLN은 공식 vLLM Profiling 가이드와 동일한 인터페이스를 지원합니다.
Note
이전에는 환경변수로 프로파일링 설정이 이루어졌으나 프로파일링을 위한 환경 변수가 deprecated되기 시작했습니다. vLLM RBLN v0.10.1부터 프로파일링 설정은 이제 LLM의 파라미터로 구성됩니다.
1.1. Offline Inference 프로파일링¶
Python 스크립트를 통한 오프라인 추론 시, start_profile()과 stop_profile() 메서드를 사용하여 측정하고자 하는 구간을 설정합니다.
1.2. Online Inference 프로파일링¶
API 서버를 이용한 online inference를 위해서 먼저 --profiler-config 옵션을 사용하여 OpenAI 서버를 실행합니다.
그 후에 별도의 엔드포인트를 호출하여 프로파일링을 제어합니다.
/start_profile엔드포인트를 호출하여 프로파일링을 시작합니다./v1/chat/completions등 실제 추론 요청을 보냅니다./stop_profile엔드포인트를 호출하여 프로파일링을 종료하고 결과를 저장합니다.
1.3 추가 옵션¶
상세한 분석을 위해 다음 변수들을 profiler_config에 추가로 설정할 수 있습니다.
torch_profiler_record_shapes: 텐서의 Shape 정보를 기록합니다. (기본값: 꺼짐)torch_profiler_with_memory: 메모리 사용량을 함께 프로파일링합니다. (기본값: 꺼짐)torch_profiler_with_stack: 소스 코드의 스택 트레이스를 기록합니다. (기본값: 켜짐)torch_profiler_with_flops: FLOPs (Floating Point Operations)를 기록합니다. (기본값: 꺼짐)torch_profiler_use_gzip: 프로파일링 파일의 gzip 압축을 제어합니다. (기본값: 켜짐)
1.4 프로파일 결과 시각화¶
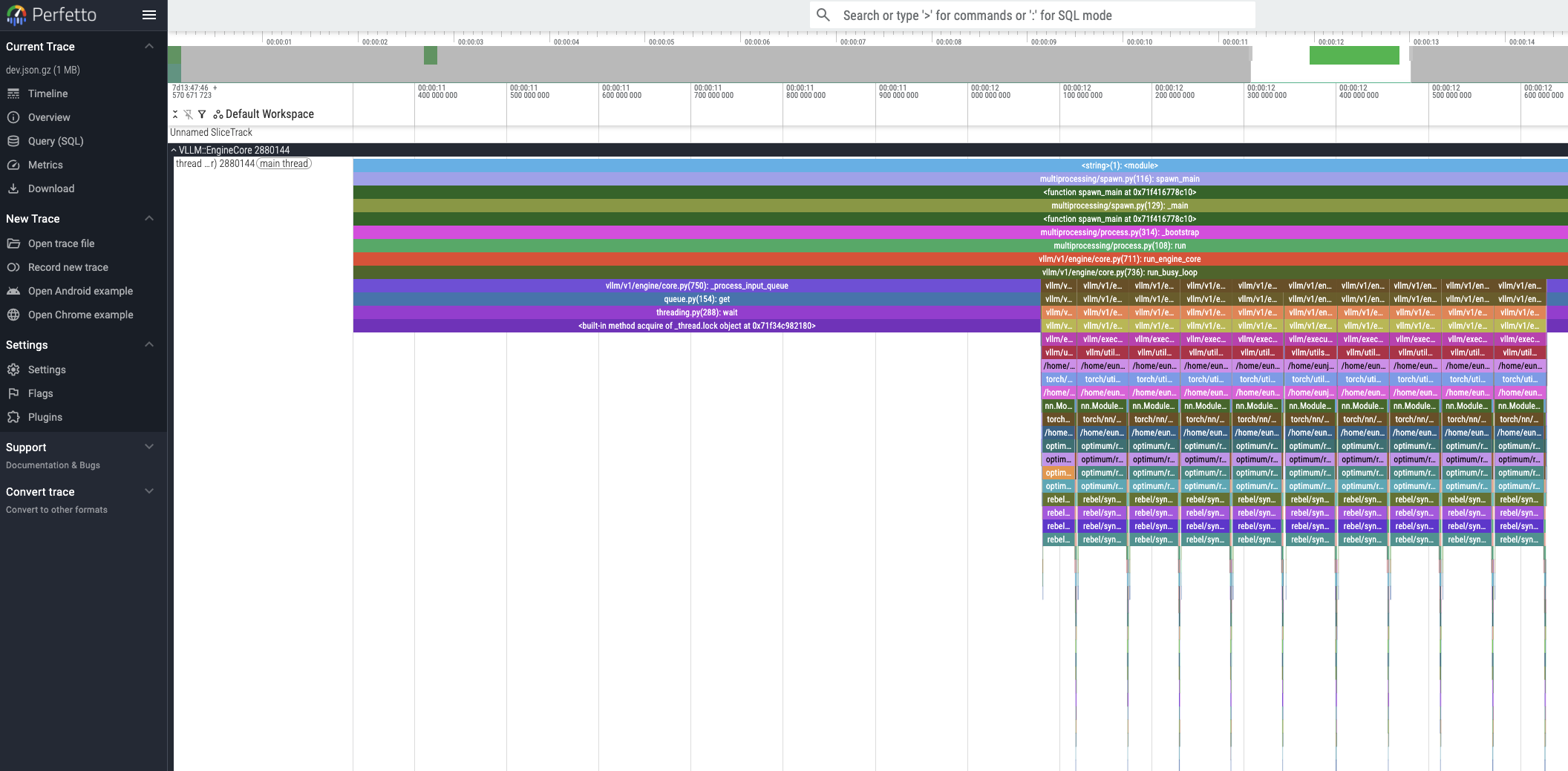
생성된 프로파일링 트레이스 파일은 Perfetto UI를 통해 시각화할 수 있습니다.
2. RBLN Profiler¶
RBLN 프로파일러는 RBLN NPU에서 실행되는 워크로드의 성능을 상세히 분석하기 위해 제공되는 소프트웨어 도구입니다. 자세한 내용은 RBLN 프로파일러를 참고 바랍니다.
2.1 제약 사항 및 설정¶
vLLM RBLN 환경에서 RBLN 프로파일러를 사용한 프로파일링은 멀티프로세스 구성이 비활성화된 상태에서만 지원됩니다.
멀티프로세싱 환경 지원은 추후 업데이트될 예정입니다.
아래와 같이 환경 변수를 설정한 후 vLLM을 실행하면 프로파일링 결과가 생성됩니다.
RBLN_PROFILER=1: RBLN 프로파일러 활성화VLLM_ENABLE_V1_MULTIPROCESSING=0: 멀티프로세싱 비활성화
2.2 프로파일 결과 시각화¶
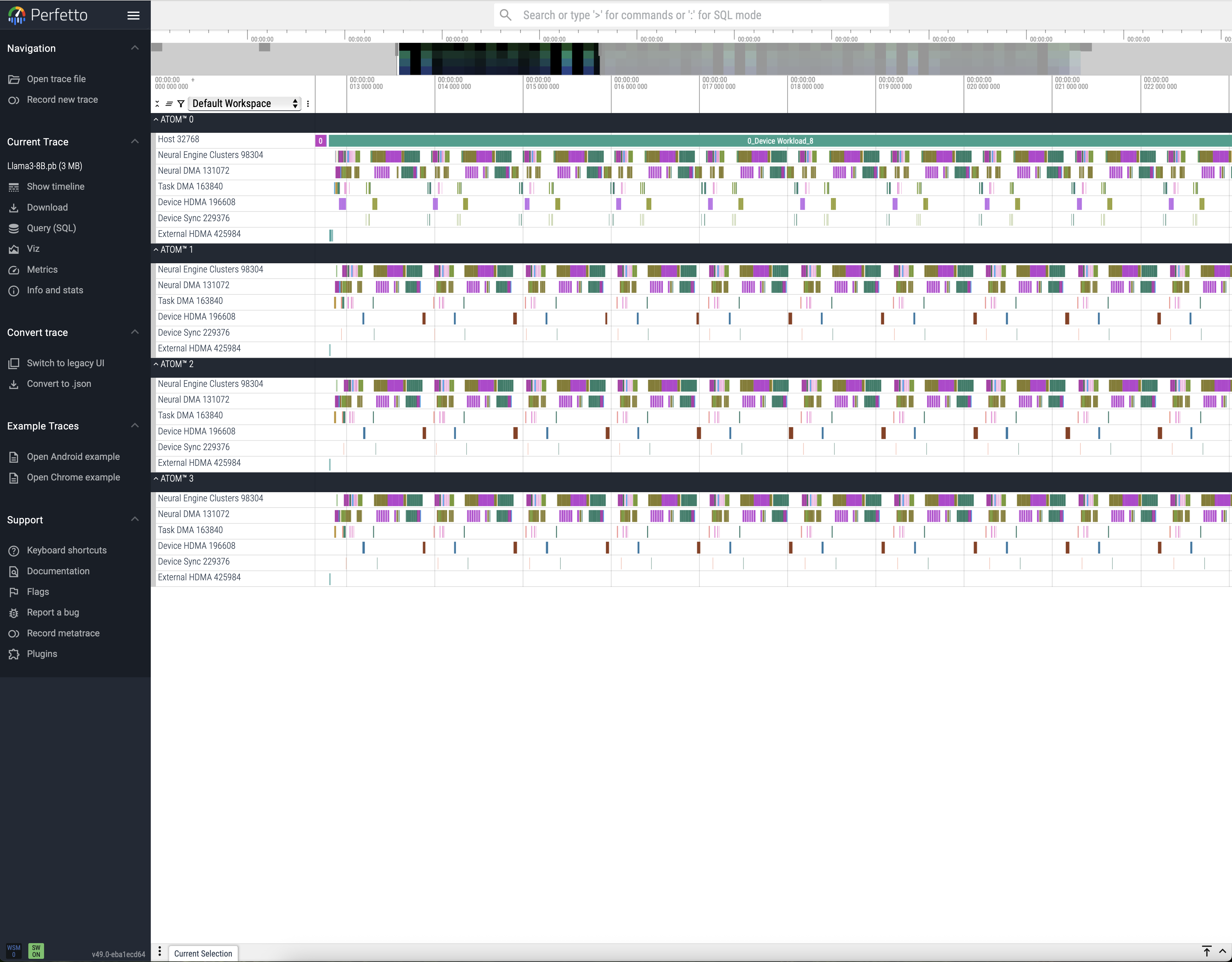
이 프로파일링 트레이스 파일도 Perfetto UI를 통해 시각화할 수 있습니다. 트레이스 분석에 대한 더 자세한 내용은 Perfetto 분석 방법 문서를 참고하십시오.