RBLNServe (Model Server)
RBLN SDK offers a model serving framework called RBLNServe, which provides RBLN model inference services using RBLN NPUs through REST and gRPC protocols. With RBLNServe, users do not need to manually employ RBLN Runtime libraries. Instead, users can run inferences through web-based interfaces, simplifying integration with other web services.
Installation
Before we start, please make sure you have prepared the following prerequisites in your system:
- Ubuntu 20.04 LTS (Debian bullseye) or higher
- RBLN NPUs equipped (e.g., RBLN ATOM)
- Python (supports 3.9 - 3.12)
- RBLN SDK (Driver, Compiler)
Then, install RBLNServe with pip using the following command. This requires access rights to Rebellions' private PyPI server:
| $ pip install -i https://pypi.rbln.ai/simple rblnserve
|
Usages
Command Line Interface
After installation, you can use rblnserve CLI with the following options:
| $ rblnserve --help
Usage: rblnserve [OPTIONS]
Options:
--host TEXT IPv4 address to bind
--rest-port INTEGER REST server port to listen
--grpc-port INTEGER GRPC server port to listen
--config-file TEXT path to model config yaml file
--version print RBLNServe version
--install-completion [bash|zsh|fish|powershell|pwsh]
Install completion for the specified shell.
--show-completion [bash|zsh|fish|powershell|pwsh]
Show completion for the specified shell, to
copy it or customize the installation.
--help Show this message and exit.
|
Serving models
Before running the RBLNServe, you need to prepare the compiled model (how to compile). Here is the example code:
| import torch
import torchvision
import rebel
# Prepare the compiled model ('resnet50.rbln' in this example)
model_name = "resnet50"
input_name = "input0"
input_shape = [1,3,224,224]
weights = torchvision.models.get_model_weights(model_name).DEFAULT
model = getattr(torchvision.models, model_name)(weights=weights).eval()
compiled_model = rebel.compile_from_torch(model, [(input_name, input_shape, torch.float32)])
compiled_model.save(model_name+".rbln")
|
Based on the compiled model /path/to/your/model/resnet50.rbln, you can create a configuration file model_config.yaml as below. You can add multiple model configurations to serve multiple models concurrently.
| models:
- name: my-model
path: "/path/to/your/model/resnet50.rbln"
version: 0.1.0 #optional
description: "ResNet50 Test" #optional
|
Now, you can run the server with the following command:
| $ rblnserve --config-file=model_config.yaml
____________ _ _ _ _____
| ___ \ ___ \ | | \ | |/ ___|
| |_/ / |_/ / | | \| |\ `--. ___ _ ____ _____
| /| ___ \ | | . ` | `--. \/ _ \ '__\ \ / / _ \
| |\ \| |_/ / |____| |\ |/\__/ / __/ | \ V / __/
\_| \_\____/\_____/\_| \_/\____/ \___|_| \_/ \___|
2023-08-16 09:46:58,809 INFO: model has been loaded: name='my-model' path='/path/to/your/model/resnet50.rbln' version='0.1.0' description='ResNet50 Test'
2023-08-16 09:46:58,822 INFO: Started server process [38167]
2023-08-16 09:46:58,822 INFO: Waiting for application startup.
2023-08-16 09:46:58,825 INFO: GRPC server listening on 0.0.0.0:8081
2023-08-16 09:46:58,825 INFO: Application startup complete.
2023-08-16 09:46:58,825 INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
|
Requesting inference via REST API
Before requesting inference, you need to prepare the json payload (payload specification). Here is the example code:
| import urllib.request
import json
import torchvision
model_name = "resnet50"
input_name = "input0"
input_shape = [1,3,224,224]
weights = torchvision.models.get_model_weights(model_name).DEFAULT
preprocess = weights.transforms()
# Prepare the json payload ('tabby.json' in this example)
img_url = "https://rbln-public.s3.ap-northeast-2.amazonaws.com/images/tabby.jpg"
response = urllib.request.urlopen(img_url)
with open("tabby.jpg", "wb") as f:
f.write(response.read())
img = torchvision.io.image.read_image("tabby.jpg")
img = preprocess(img).unsqueeze(0).numpy()
input_data = img.flatten().tolist()
payload = {
"inputs": [
{
"name": input_name,
"shape": input_shape,
"datatype": "FP32",
"data": input_data
}
]
}
with open("tabby.json", "w") as f:
json.dump(payload, f)
|
Based on the json payload example /path/to/your/payload/tabby.json, you can send a request using one of the following methods:
Python requests
| import requests
import json
url = "http://localhost:8080/v2/models/my-model/versions/0.1.0/infer"
with open("/path/to/your/payload/tabby.json", "r") as f:
payload = json.load(f)
response = requests.post(url, json=payload)
print(response.json())
|
NodeJS axios
| var axios = require("axios");
var fs = require("fs");
var payload = fs.readFileSync("/path/to/your/payload/tabby.json");
var config = {
method: "post",
url: "http://localhost:8080/v2/models/my-model/versions/0.1.0/infer",
headers: {
"Content-Type": "application/json"
},
data: payload
}
axios(config)
.then(function (response) {
console.log(response.data);
})
.catch(function (error) {
console.error(error);
})
|
curl
| $ curl -X POST -H "Content-Type: application/json" -d "@/path/to/your/payload/tabby.json" http://localhost:8080/v2/models/my-model/versions/0.1.0/infer
|
Requesting inference via gRPC API
Before using gRPC API, you need to generate pb2 codes based on the KServe grpc proto file. Please refer the gRPC documentation to generate your own pb2 codes for Python or any other languages you want. Otherwise, you can directly use pb2 modules provided by rblnserve from rblnserve.api.grpc.predict_v2_pb2 and rblnserve.api.grpc.predict_v2_pb2_grpc.
Assuming you've already prepared the input tensors as described above, you can use one of the following methods (or any languages and libraries supporting gRPC) to send a request:
Python grpcio
| import grpc
# import your generated pb2 files
import your.modules.generated_pb2 as pb2
from your.modules.generated_pb2_grpc import GRPCInferenceServiceStub
channel = grpc.insecure_channel("localhost:8081") # replace with your rblnserve grpc endpoint
stub = GRPCInferenceServiceStub(channel)
# prepare your preprocessed inputs
input_data = ...
request = pb2.ModelInferRequest(
model_name="my-model",
model_version="0.1.0",
inputs=[
pb2.ModelInferRequest.InferInputTensor(
name="input0",
shape=[1, 3, 224, 224],
datatype="FP32",
contents=pb2.InferTensorContents(fp32_contents=input_data),
)
],
)
response = stub.ModelInfer(request)
|
NodeJS grpc-js
| const grpc = require("@grpc/grpc-js");
const protoLoader = require("@grpc/proto-loader");
const packageDefinition = protoLoader.loadSync("path_to_proto_file.proto", {
keepCase: true,
longs: String,
enums: String,
defaults: true,
oneofs: true,
});
const protoDescriptor = grpc.loadPackageDefinition(packageDefinition);
const service =
protoDescriptor.your.modules.generated_pb2_grpc.GRPCInferenceService;
const client = new service(
"localhost:8081", // replace with your rblnserve grpc endpoint
grpc.credentials.createInsecure()
);
// prepare your preprocessed inputs
const input_data = ...
const request = {
modelName: "my-model",
modelVersion: "0.1.0",
inputs: [
{
name: "input0",
shape: [1, 3, 224, 224],
datatype: "FP32",
contents: { fp32Contents: input_data },
},
],
};
client.ModelInfer(request, (error, response) => {
if (error) {
console.error(error);
return;
}
console.log(response);
});
|
API endpoints
The API endpoints served by RBLNServe are compliant with KServe Predict Protocol V2.
REST API
| endpoint |
description |
GET /v2 |
Returns server metadata (link) |
GET /v2/health/live |
Returns server liveness (link) |
GET /v2/health/ready |
Returns server readiness (link) |
GET /v2/models/{MODEL_NAME} |
Returns a model metadata specified by MODEL_NAME (link) |
GET /v2/models/{MODEL_NAME}/ready |
Returns a model readiness specified by MODEL_NAME (link) |
POST /v2/models/{MODEL_NAME}/infer |
Returns inference results of a model specified by MODEL_NAME (link) |
GET /v2/models/{MODEL_NAME}/versions/{MODEL_VERSION} |
Returns a model metadata specified by MODEL_NAME and MODEL_VERSION (link) |
GET /v2/models/{MODEL_NAME}/versions/{MODEL_VERSION}/ready |
Returns a model readiness specified by MODEL_NAME and MODEL_VERSION (link) |
POST /v2/models/{MODEL_NAME}/versions/{MODEL_VERSION}/infer |
Returns inference results of a model specified by MODEL_NAME and MODEL_VERSION (link) |
You can also review and test REST APIs as described in the Swagger documentation page, which is accessible through http://localhost:8080/docs:
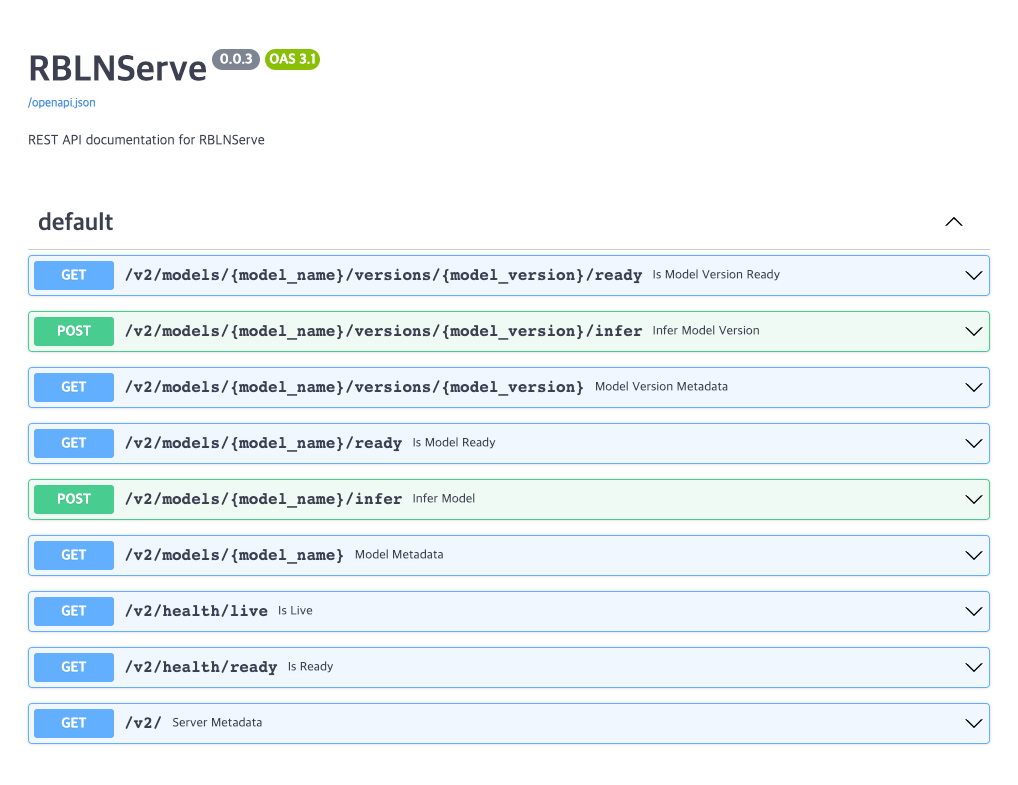
gRPC API
| rpc |
description |
ServerMetadata |
Returns server metadata (link) |
ServerLive |
Returns server liveness (link) |
ServerReady |
Returns server readiness (link) |
ModelMetadata |
Returns a model metadata specified by name and version (link) |
ModelReady |
Returns a model readiness specified by name and version (link) |
ModelInfer |
Returns inference results of a model specified by name and version (link) |
Note that RBLNServe gRPC server supports server reflection, so you can inspect the service definition using tools such as Postman.