vLLM RBLN: RBLN NPU용 vLLM 플러그인¶

vLLM RBLN(vllm-rbln)은 리벨리온 NPU를 위한 vLLM용 하드웨어 플러그인으로, 고성능 LLM 추론 및 서빙을 지원합니다.
설치 방법¶
vLLM RBLN을 설치하기 이전에 반드시 rebel-compiler 최신 버전을 설치해야 합니다.
vLLM RBLN은 PyPI에서 설치하거나 소스 코드를 직접 빌드하여 설치하는 두 가지 방법을 제공합니다.
PyPI로 설치하기¶
다음은 pip를 통해 최신 릴리즈를 설치하는 명령어입니다.
소스 코드 빌드 후 설치하기¶
1. vllm과 vllm-rbln 저장소 클론¶
vllm의 버전 번호는 vllm-rbln에서 사용되는 버전 번호와 일치하지 않음에 유의해야 합니다.
2. vllm 설치¶
VLLM_TARGET_DEVICE=empty는 설치 시 타깃 디바이스 설정을 생략하고 빌드만 진행하도록 하는 옵션입니다.
3. vllm-rbln 설치¶
최신 버전 및 변경 사항에 대한 자세한 내용은 릴리즈 노트를 참고하세요.
아키텍처 디자인¶
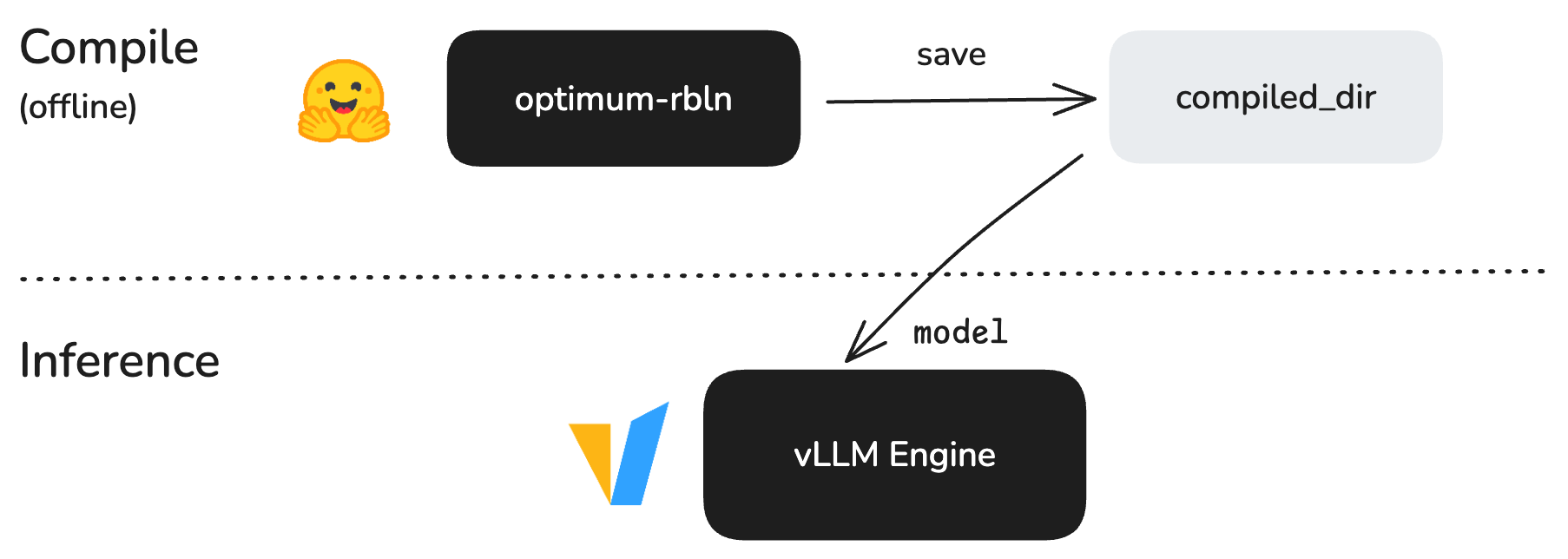
현재 vLLM RBLN은 optimum-rbln을 기반으로 작동합니다. 사용자가 optimum-rbln으로 모델을 미리 컴파일한 뒤, 그 디렉토리를 model 파라미터로 vLLM에 전달합니다. 이 방식이 현재까지 기본이자 안정적인 워크플로우이며, 모든 튜토리얼과 예제는 이를 기반으로 작성되어 있습니다.
vLLM RBLN v0.10.4부터는 optimum-rbln의 컴파일 단계를 vLLM RBLN이 자동으로 처리하는 베타 기능을 지원합니다. LLM()에 엔진 파라미터를 직접 전달하면 엔진 시작 시 컴파일이 진행되어, 별도의 사전 컴파일 단계가 필요 없습니다.
Torch Compile 기반으로의 전환¶
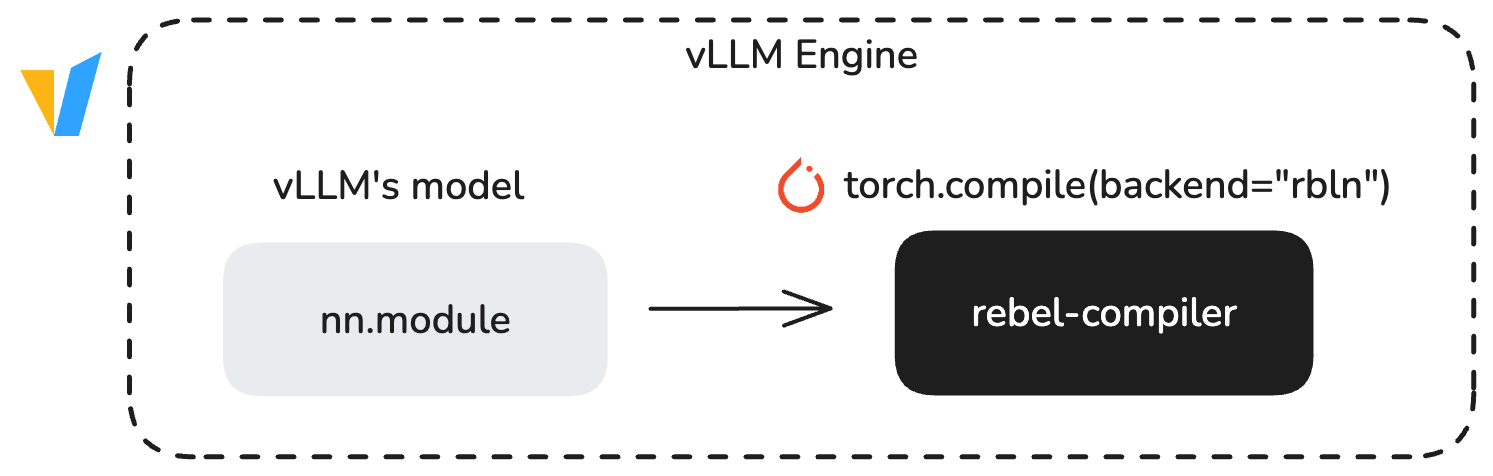
torch.compile()을 활용해 vLLM의 기본 모델 구현과 API에 곧바로 통합되는 새로운 아키텍처로 마이그레이션이 진행 중입니다. optimum-rbln 경로는 지원하는 각 모델 아키텍처에 대해 RBLN 전용 모델 클래스(예: RBLNLlamaForCausalLM)를 제공하는 반면, 이 새로운 아키텍처는 PyTorch의 표준 torch.compile 백엔드 메커니즘을 그대로 활용해 upstream vLLM/PyTorch 생태계와 자연스럽게 어울립니다.
torch.compile()을 사용하면 첫 실행 시 모델이 컴파일되는 콜드 스타트(cold start)가 발생합니다. 이 때 컴파일 결과는 캐시에 저장되며, 이후 실행은 웜 스타트(warm start)로 처리되어 더 빠르고 최적화된 성능을 제공합니다.
튜토리얼 및 주요기능¶
vllm-rbln을 쉽게 시작할 수 있도록, 기본적인 기능과 다양한 배포 옵션을 보여주는 튜토리얼을 제공합니다.
- 모델 튜토리얼: 대표적인 모델을 기반으로 vLLM RBLN 실행 과정을 단계별로 따라할 수 있는 튜토리얼을 제공합니다.
- 기능 소개: 다양한 실행 모드와 서버 기능등 vLLM RBLN이 제공하는 핵심 기능들을 설명합니다.
지원하는 모델 목록¶
다음은 vLLM RBLN이 현재 지원하는 모델 목록입니다.
Decoder-only Models¶
| Architecture | Example Model Code |
|---|---|
| RBLNLlamaForCausalLM | Llama-2/3 |
| RBLNGemmaForCausalLM | Gemma |
| RBLNGemma2ForCausalLM | Gemma2 |
| RBLNPhiForCausalLM | Phi-2 |
| RBLNOPTForCausalLM | OPT |
| RBLNGPT2LMHeadModel | GPT2 |
| RBLNMistralForCausalLM | Mistral |
| RBLNExaoneForCausalLM | EXAONE-3/3.5 |
| RBLNQwen2ForCausalLM | Qwen2/2.5 |
| RBLNQwen3ForCausalLM | Qwen3 |
| RBLNGptOssForConditionalGeneration | gpt-oss |
Encoder-Decoder Models¶
| Architecture | Example Model Code |
|---|---|
| RBLNWhisperForConditionalGeneration | Whisper |
변경 사항
vLLM RBLN v0.10.1부터 V0는 더 이상 지원되지 않습니다. 이에 따라 encoder–decoder 모델로는 Whisper만 지원되며, 그 외 모든 encoder–decoder 모델에 대한 지원은 제거되었습니다. 자세한 내용은 vLLM V1 사용자 가이드를 참고하세요.
Multimodal Language Models¶
| Architecture | Example Model Code |
|---|---|
| RBLNLlavaNextForConditionalGeneration | LlaVa-Next |
| RBLNQwen2VLForConditionalGeneration | Qwen2-VL |
| RBLNQwen2_5_VLForConditionalGeneration | Qwen2.5-VL |
| RBLNQwen3VLForConditionalGeneration | Qwen3-VL |
| RBLNIdefics3ForConditionalGeneration | Idefics3 |
| RBLNGemma3ForConditionalGeneration | Gemma3 |
| RBLNLlavaForConditionalGeneration | Llava |
| RBLNBlip2ForConditionalGeneration | BLIP2 |
| RBLNPaliGemmaForConditionalGeneration | PaliGemma |
| RBLNPaliGemmaForConditionalGeneration | PaliGemma2 |
Pooling Models¶
| Architecture | Example Model Code |
|---|---|
| RBLNT5EncoderModel | T5Encoder-based |
| RBLNBertModel | BERT-based |
| RBLNRobertaModel | RoBERTa-based |
| RBLNXLMRobertaModel | XLM-RoBERTa-based |
| RBLNXLMRobertaForSequenceClassification | XLM-RoBERTa-based |
| RBLNRobertaForSequenceClassification | RoBERTa-based |
| RBLNQwen3ForCausalLM | Qwen3-based |
| RBLNQwen3Model | Qwen3-based |